Hey everybody,
I currently have a problem and try to seek advice from you. I do really hope you are able to help me or tell me where I took the wrong lane. 
Over the course of the last few weeks and months me and my colleagues have been working on getting Camunda to run in our use case scenarios. Well it runs but we are not satisfied with the performance at all.
To maybe make clear what we are facing:
Let’s say we have a business process with just a single activity.
That business process will always be started a few hundred thousand if not million times.
That activity is just meant to be a delegate to a REST based micro service that is able to handle a batch request in a matter of seconds if not milliseconds (we invested a lot of time and effort into getting it to the point it is that fast).
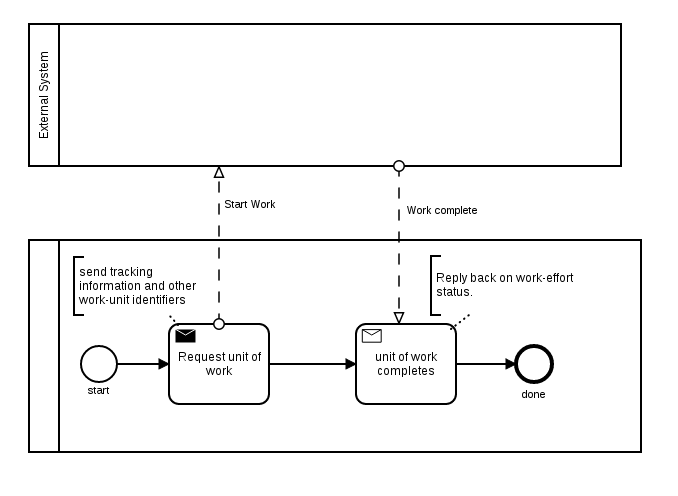
The activity is marked as an external task with a topic, input / output defined, and so on.
I implemented a simple solution, based on reactive streams that polls the programmatic API of the ExternalTaskService for that specific topic and tries to fetchAndLock a pre-defined number of external tasks.
Individual request objects of each external task are aggregated into a single batch request and a REST-call is sent to the micro-service. The result is then split into individual responses again and corresponding external tasks are completed, one after another, individually, programmatically at the ExternalTaskService.
So fas so good. Luckily, polling seems okay and does not cost that much performance (as fas as I have observed). Sadly, completing each individual external task takes just ages. On a medicore laptop it takes 10 to 30 seconds to complete around 500 to 600 external tasks, with a h2 in-memory db. Even longer with a production grade Oracle database in the background.
While that single endpoint of our system (the microservice I talked about) takes a few seconds at most to make significant computations for millions of customers on that medicore laptop, the performance of that task completion is just not what we can accept. I understand that state has to be persisted, and so on and I am okay with that. I would just not have thought that we’d have such a significant drop in performance by taking that route.
The production scenario will most likely be more complex diagrams and 1 to n aggregations for many more activities. While not exclusively the use case, we wanted to use that pattern (aggregation and batch processing) still a lot. This leads to the problem that we have following tasks that will have to wait until the previous activity is completed for all customers or we will have to take smaller batches.
Are external tasks the wrong tool for that use case? Did I or did we miss some kind of configuration parameters?
I’m really looking forward to your replies. Thank you for your invesment of time, in advance!