Hello,
I am developing an application which has to send a large number of emails - up to half a million at once.
Does it make sense to use camunda tasks to handle individual email delivery (with possible retries)?
If it does - what are the important points I have to deal with to not kill the server with it?
Thanks
Andrius
1 Like
Hi @andrius
Welcome to the forum 
On the face of it, this isn’t an unusual use case but there are a lot of things to consider when it comes to implementation. Generally if you’d doing something like sending an load of emails it’s going to need a lot of threads running - So you’d need to have a clustered setup where the engine access to more threads. But shouldn’t be a problem.
Thanks Niall,
currently I’m leaning towards simple java loop implementation.
Clustered setup with lots of threads seems little more involved 
Andrius
Clustering is really straight-forward you just need to spin up a few extra instance of the engine point them all to the same DB and they will magically form a cluster, you don’t even need to change any settings.
It’s also way more reliable.
If you run a loop for that kind of volume you’re going to possibly get a thread timeout and errors are going to be harder to fix.
1 Like
I have started the Camunda based implementation and I am puzzled if Camunda is suitable for managing many short-lived parallel tasks.
I was trying to send individual emails in the multi-instance taks and I was getting many OptimisticLockingExceptions causing the emails being sent repeatedly. So I read a bit about optimistic locking in Camunda and I got an impression there is little I can do about it.
The only useful thing I was able to do was to make everything asynchronous. That prevented the emails to be sent repeatedly. But the OptimisticLockingExceptions were still generating multiple warnings and they were causing large delay in finishing the multi instance task - maybe because the tasks themselves were very quick and they always came concurrently to the finish line.
When trying to send 10 emails, I always get 45 OptimisticLockingException warnings, which is exactly 9+8+7+6+5+4+3+2+1. Imagine what it will do with 100000 instances…
Although it sends emails quite fast, the finishing of the multi-instance task itself has a huge overhead. How can I avoid it?
Here is my very simple model:
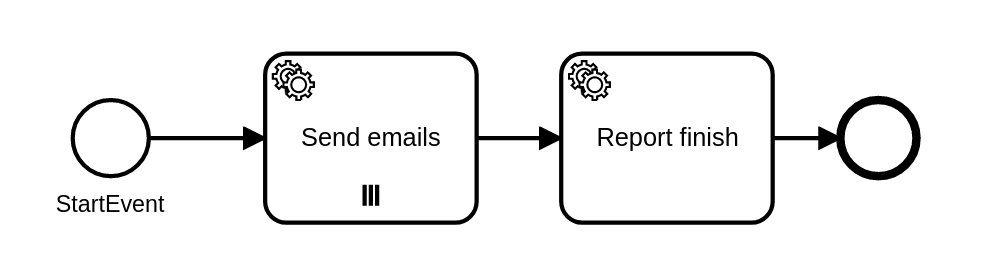
email.bpmn (3.2 KB)
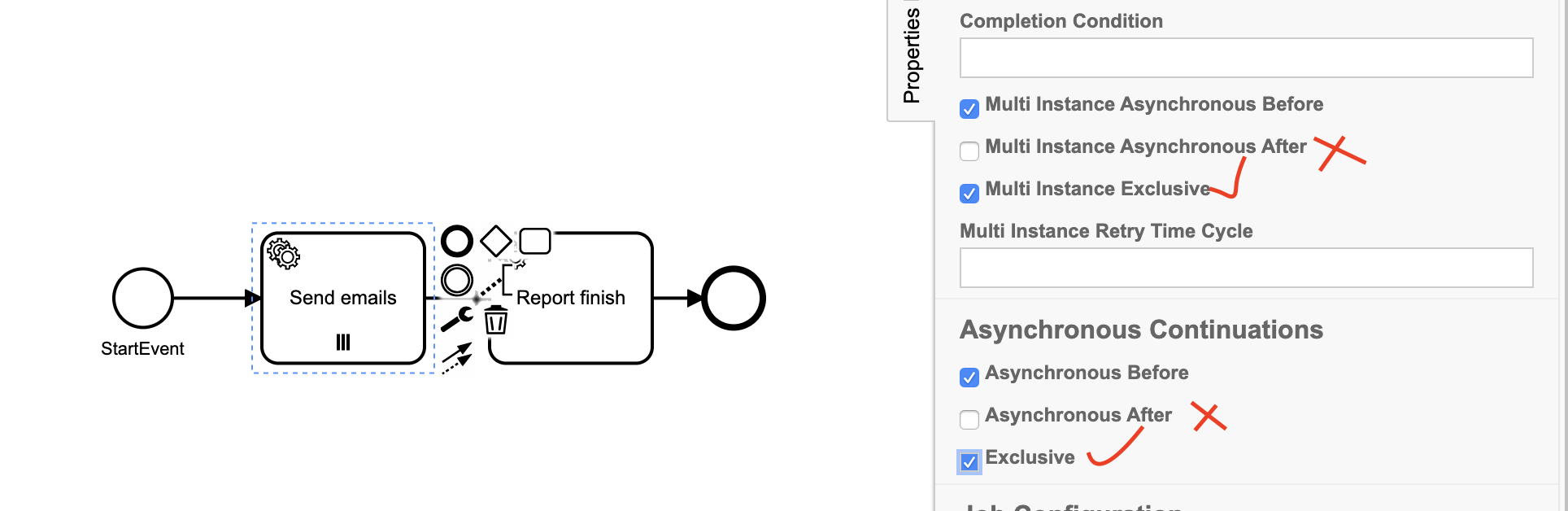
I definitely do not want exclusive sending. I really want it parallel, because it is much much faster.
It seems Camunda has some official suggestion for this particular problem: Performance tuning Camunda 7 | Camunda Platform 8
Unfortunately, suggested solution seems to be outside Camunda:
- use an external activity for performing parallel tasks
- use separate DB table to gather the results and track progress.
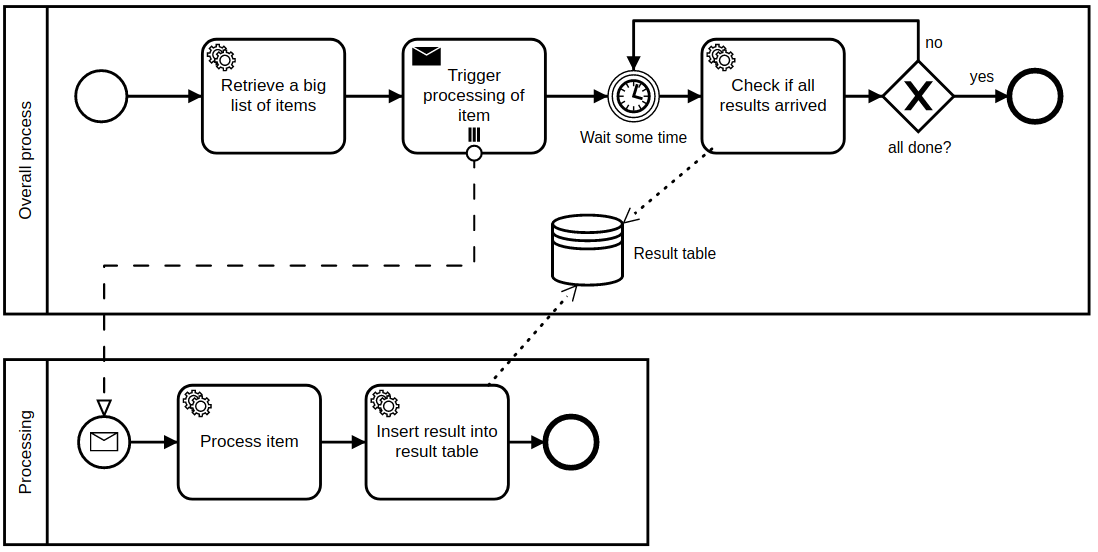
Yes, optimistic locking is a problem for mass processing.
There few tricks with it, instead making it sequential.
-
Here is node.js worker example. It uses strategy commit few (I use 3) times a task instead failing on first optimistic locking:
camunda-plugins/InternalService.js at master · MaximMonin/camunda-plugins · GitHub
In my case it solved 99.9% of optomistic locking issues. -
Use subprocess miltiinstance instead multiinstance task. It creates parallel subprocesses with it own context and there are no chance to optimistic locking.
Thanks, Maxim, for you reply, but:
- I did not read about externals tasks until now. As I understand, the optimistic locking problem occurs with them at
complete(). So the hope of being able to complete after retrying is based on the assumption that there aren’t many other concurrent workers trying tocomplete()at the same time? - Why does subprocess multiinstance make any difference? In my understanding, sub or no sub - the problem remains the same - Camunda has to gather all the parallel instances which it does using optimistic locking strategy. If there are several executions concurrently at the subprocess end - all except one get an
OptimisticLockingException? Don’t they? The performance tuning document mentions that subprocess even makes it worse by doubling the execution tree. Doesn’t it?
Now I’m leaning towards trying the DB table for job states and checking if they all finished.
- yes complete() it is not only commiting current task, but also finding other job and task after commiting up to next savepoint. And it is all in one transaction. It is why complete() takes a time, sometimes 30-60ms. I use idea, that if rest api returns 500 Optimistic locking, I repeat commit on this error, after 30ms for example. And this try can be succesful. No matter how many parallel workers doing its jobs.
- You can use asyncAfter in subprocess activity, then mailng task commiting inside subprocess and saves new transaction point and Opens new transaction. So all tasks can send mail in parallell, but in the exit of subprocess can be optimisic locking, but you saved and exucuted your task already.
Yes call of subprocess activity takes about 20ms on enter and 20 ms on exit.
asyncAfter before paralell joins or in parallel multiinstance very useful.
So all tasks can send mail in parallell, but in the exit of subprocess can be optimisic locking, but you saved and exucuted your task already.
Yeah, I already figured it out with the asynchAfter thing. It works equally well without the subprocess.
I am not happy with the result nevertheless, because after sending all the emails in parallel, I have to wait until all the optimistic locks get resolved. This automatic resolution takes even more time and resources than tasks themselves, because there are much more optimistic lock failures that the tasks.
I tried the approach like suggested in best practices guide - to create individual processes for batch items:
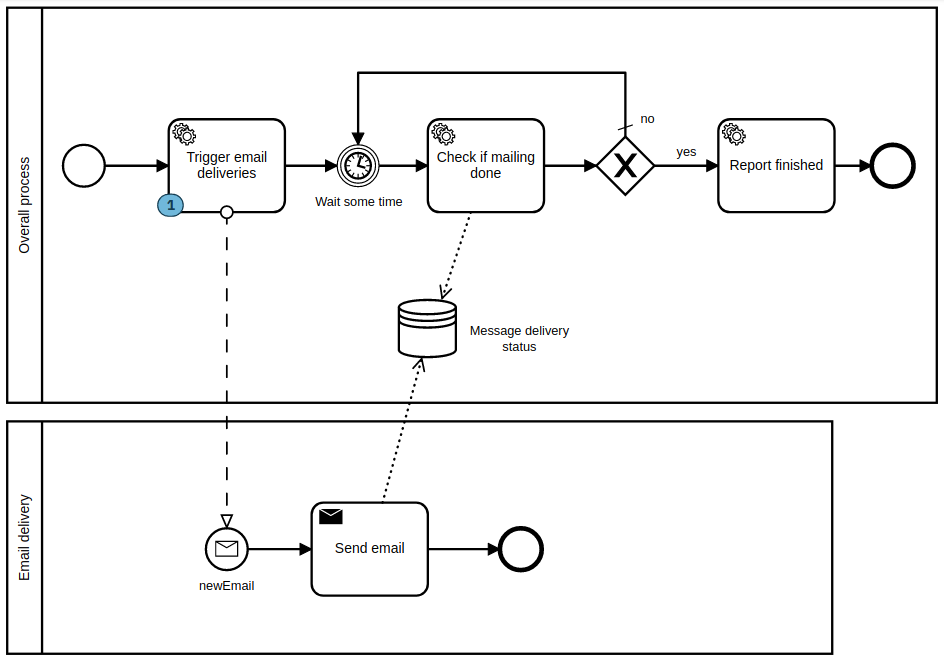
It worked for small number of items (10000). But when trying with a larger number (100000), the initial “Trigger email deliveries” task takes more than 5 minutes and then it times out.
It seems Camunda is not very fast at sending messages and creating new process instances. I will try to change this model slightly and use message subprocess instead of separate participant process. Let’s see if it helps. I suspect it won’t be radically faster ![]()
Andrius
I just tried the message subprocess version:
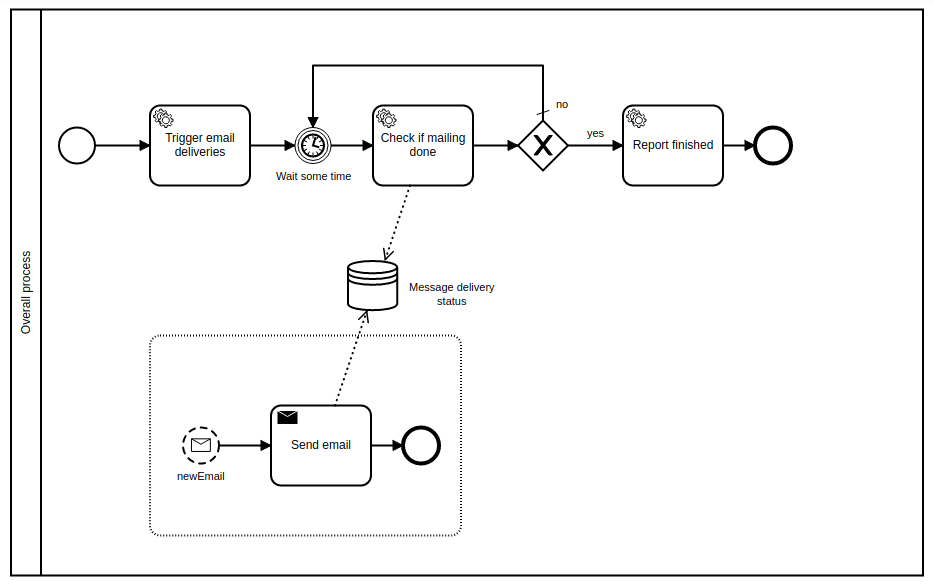
Now, triggering (sending messages) works surprisingly fast - it can send 1000 messages in 3 seconds on my PC. But I have now two new problems:
- The all executions of “Send email” task get the same values as local variables. Why? Isn’t subprocess supposed to have its own variable scope? How do I pass different email values with those trigger messages?
My current correlation code is this:
runtimeService.createMessageCorrelation("Message_newEmail")
.processInstanceBusinessKey("37")
.setVariablesLocal(
Map.of(
Variable.MESSAGE.varName, message,
Variable.CUSTOMER_QUERY_RESULT.varName, customerQueryResult)).correlate();
- I started to get
OptimisticLockingExceptions. No. Not again. Why does Camunda need to lock something when executing subprocess for an uninterruptible message?
Is there any trick which will fix everyhing for me?
![]()
Ok, I was able to solve the first issue using some listener magic suggested here: Set local variables in event subprocess via REST-API - #9 by Marc1
It seems unnatural not being able to send local vars to event subprocess in a civilized manner. Others are also complaining about it:
https://jira.camunda.com/browse/CAM-10380
https://jira.camunda.com/browse/CAM-10680
I’m still not able to deal with the evil OptimisticLockingException problem. Why oh why Camunda needs any locking on event subprocesses started by uninterruptible message event? Resolving those locking problems kills the performance when dealing with many small items.
How do I work around it?
I think, that camunda is not good enough for iterations of very large array of elements. It creates too many records in db for it:
activity record, job record, external task record, variable change record, variable values record and more…
It makes strong impact to db size. It is why in cases of very large arrays I prefer save all array in redis, with all sets of data, and run 1 external task, that iterates everything. Yes i know it can be a problem if something fails.
Btw check zeebe project. Zeebe works very well with multi parallel and parallel joins jobs. It doesnt use db and no optimistic locking problem there. And it iterates really fast.
Thank you Maxim. I looked at zeebe github page, but I did not really understand, how is it related to Camunda. Is it a fork or reimplementation of Camunda? Does it have a similar interface?
Hi @andrius
Yeah, this is a pain for sure, optimistic locking is the price we pay for guaranteed consistency of state. So they’ll never go away entirely. The good news is that with every release we work on trying to reduce their occurrence and the we defiantly have multi-instance in our sites for improvements.
Zeebe is another engine that we at Camunda built. As @MaximMonin mentioned it has fundamental design choices that makes it perfect for very, very high through put. Another nice thing about it is that you can use Camunda Cloud and camunda will host the instance so you don’t need to set it up.
It is different engine, based on facebook raft, + exporters to elastic search as logger. It has modeller almost the same to camunda modeller but with subset of elements and properties. And mostly use external task workers to execute model.
1 Like