Hi all,
my BPM processes start always with an initial Json payload.
String incomingJsonPayload = ...
Map<String, Object> variables = new HashMap<>();
variables.put("payload", incomingJsonPayload ); //using string
//variables.put("payload", org.camunda.spin.Spin.JSON(incomingJsonPayload)); //using Json/Spin
processEngine.getRuntimeService().startProcessInstanceByKey(btProcessName, variables);
As you see in the code snippet, I’m not sure if I should always convert my incomingJsonPayload to a SpinJsonNode object. The handling of Json data and the converting in Java objects is done by existing, optimized libraries in my application. Therefore, I have normally no need for the features of camunda-spin.
Nevertheless, I like the EL in BPMN conditions with Spin like (${customer.jsonPath("$.adress.post code").numberValue() == 1234}.
Furthermore, I use SpinJsonNode also to avoid problems with big payloads (>4000 chars, database constraints).
But SpinJsonNode data are stored as blob inside the database, which gives me not the best feeling (e.g. extract data, Oracle dump, performance, and so on …).
Is there a general recommondation how to handle Json payload in CamundaBPM?
(like: json payload use always SpinJsonNode?)
What are your experiences by using Spin?
Is there an performance impact by using Spin that are stored in Blobs?
@matthias.reining
some reference:Any Benefits of using Spin over Javascript Objects when using javascript Scripting
String fields have a hard limit of 4000 characters. So JSON/SPIN object is the way you want to go.
I am a heavy users of SPIN/JSON, the only major downside is that JSON variables are not indexed. So you cannot use the camunda api to search for specific variables or process instances that have a value inside of a JSON variable. The workaround for this is to store your string variables in addition to your JSON variable when you need certain data to be searchable.
Also from the Rest API side, when camunda returns a JSON variable’s value it is stringified. So you have to preform a JSON parse operation with the returns json string value. (just a extra step).
Whats the type of json data you are storing? Whats your use case?
1 Like
@matthias.reining also are you using Camunda for long term storage of your json data? like the system of record?
@StephenOTT no. It’s just for save points and async processes
We use the same use case, and in prod run a lot of transactions. To date it has scaled well. No issues.
One thing we have played with is only storing “markers”/UUIDs to “data” which is stored in a key/value db. Then you do GET/POST to that KV store using the UUIDs. Basically removes the need for storing JSON, but does add some HTTP/scripting overhead
1 Like
@StephenOTT: Thanks for your feedback 
My use case / process: issue an insurance policy.
There are data from an insurance proposal that build the initial payload. Than the BPM process calls different services like data validation, partner, policy and accounting services, document (pdf) generation, email and so on…
If a service is not available, the process stops/fail and can be restarted later. Therefore the save points.
Did I get you right: you’re using in general the JSON/Spin for a lot of transactions and only for some special tests you have a have used a KV store for the JSON payload?
When you talk about “a lot” of transactions, could you give me some figures?
We have used the KV store just as a prototype of another way to store date.
The JSON is what we use for pretty much all processes. largest would be a few million instances stored on a clustered mssql. With 10-20 JSON variables per instance with various sizes of data. History Time to Live is also used utilized for longer periods to keep the older data.
It would be pretty easy to write a Unit test that loads up your database with something like SpockFramework using Datatables/Iterators plus something like this: Camunda-Spock-Testing/BasicExample/src/test/groovy/4_SpinJsonTest/SpinJsonSpec.groovy at master · DigitalState/Camunda-Spock-Testing · GitHub
and
but swap the data table out for this style: Data Driven Testing
Just a simple option to test what your load would look like
1 Like
@StephenOTT: thanks for the figures! With this data, I have a much better feeling to goahead with Spin
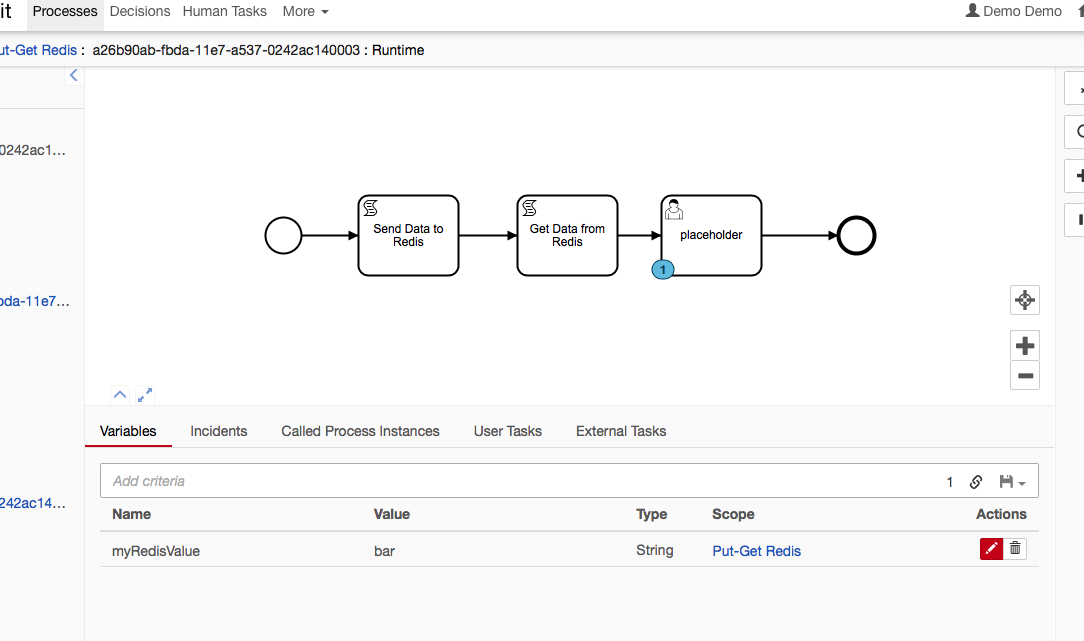
If you want to try the KV store example, i just uploaded a small sample of the the Redis example i mentioned:
Run docker-compose up --build
it will run camunda 7.8 + latest redis with a shared network.
run docker-compose down -v when finished.
Where the myRedisValue was pulled from the redis db.
Send to Redis:
var Jedis = Java.type('redis.clients.jedis.Jedis')
var jedis = new Jedis("redisdb")
jedis.set("foo", "bar")
get from redis:
var Jedis = Java.type('redis.clients.jedis.Jedis')
var jedis = new Jedis("redisdb")
var value = jedis.get("foo");
execution.setVariable('myRedisValue', value)
see the JS and BPMN for the specific context: https://github.com/DigitalState/camunda-variations/tree/master/jdis-redis/bpmn
edit: and as with pending updates to jedis for redis module command support, it will mean very easy management of reJson support (http://rejson.io / RedisJSON - Use Redis as a JSON Store | Redis)
And you can use Redis namespaces or multiple-databases in the single Redis Server Instance to support variable storage isolation between process instances
The idea being:
You could easily run these scripts as Input/Output mappings on a task and push and pull data from something like redis with very little code.
2 Likes