Bad news - this problem is occurring again.
Back in August, as suggested by thorben, we deactivated the deploymentAware setting. The current setting in our bpm-platform.xml is: <property name="jobExecutorDeploymentAware">false</property>
For several months, we have not had any problems. However just recently the same problem we originally reported is occurring again. Previously, if we deployed a new version of the model that was getting hung, subsequent instances would run fine. Now however, deploying a new version does not clear up the problem.
So far, we can not find a pattern to the problem. When we bring up a new server, it seems that things run fine for a while, but then suddenly the workflow model in question will no longer execute the async service task. Once we get in this state, it seems the only way to resolve it is to tear down the server and bring up a new one.
To demonstrate the problem I have created a modified version of the Camunda http-connector example. I have uploaded this model. invokeRestService.src.bpmn (11.7 KB)
Also, here is the ACT_RU_JOB table entry for one of the stuck instances:
# ID_, REV_, TYPE_, LOCK_EXP_TIME_, LOCK_OWNER_, EXCLUSIVE_, EXECUTION_ID_, PROCESS_INSTANCE_ID_, PROCESS_DEF_ID_, PROCESS_DEF_KEY_, RETRIES_, EXCEPTION_STACK_ID_, EXCEPTION_MSG_, DUEDATE_, REPEAT_, HANDLER_TYPE_, HANDLER_CFG_, DEPLOYMENT_ID_, SUSPENSION_STATE_, JOB_DEF_ID_, PRIORITY_, SEQUENCE_COUNTER_, TENANT_ID_
'cef61540-be55-11e6-ba32-0242ac120003', '1', 'message', NULL, NULL, '0', 'cef5ee2e-be55-11e6-ba32-0242ac120003', 'cef5c717-be55-11e6-ba32-0242ac120003', '559c8fbd-be55-11e6-b2b3-0242ac120003', '_c2ab1f62-ecd4-4401-96c2-0f67552b1b2a', '3', NULL, NULL, NULL, NULL, 'async-continuation', 'transition-create-scope', '558fe58b-be55-11e6-b2b3-0242ac120003', '1', '559c8fbe-be55-11e6-b2b3-0242ac120003', '0', '1', '7d48ec6a-2144-4535-b54c-2c23e703f3e1'
Here is a screen shot of the cockpit showing instances stuck on the service task:
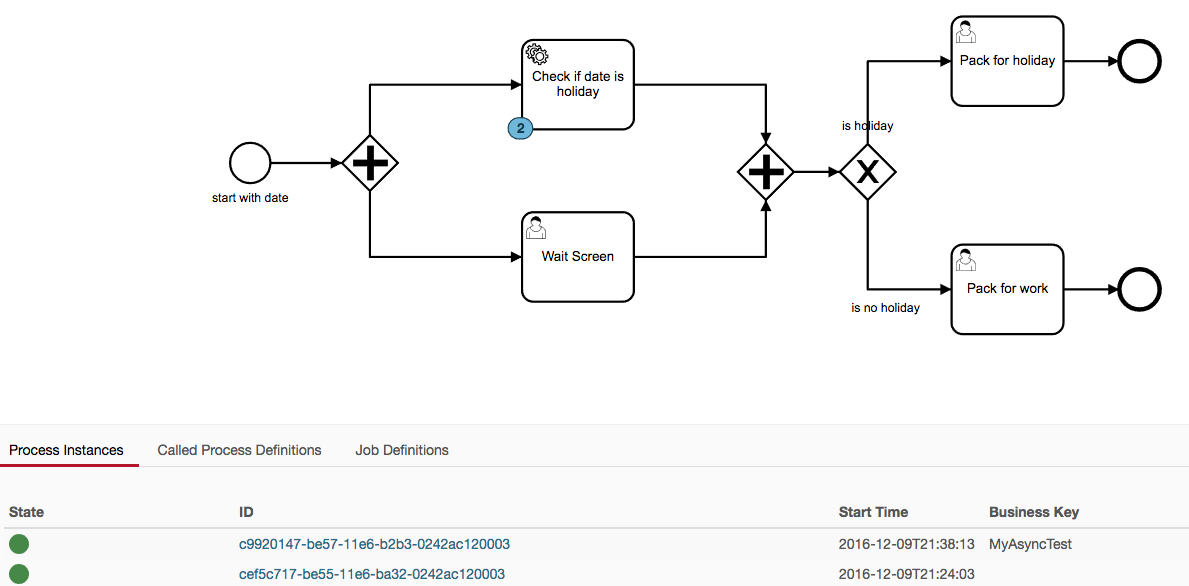
Note one item I did not previously mention, we are deploying the docker versions of the Camunda engine, but with our modifications to bpm-platform.xml. Otherwise, our environment is the same as reported previously in this thread.
Please let me know what additional information I can provide to help solve this issue. Any suggestions for other things we should investigate would be helpful.
