Ok, I am going to try deactivating the deploymentAware setting. Thank you very much for your help.
@thorben
Have you experienced this using the docker container as a dev environment?
We have experienced this above behaviour, essentially:
But all inside of the default settings docker container that is provided at GitHub - camunda/docker-camunda-bpm-platform: Docker images for the camunda BPM platform.
Looks like the job executor has problems where you start and stop the container.
Anyone else experience this?
Confirmed. If you run docker container with elements that are async, restart the container, the process engine logic that detects previous versions of a deployment does not seem to function.
These are processes deployed through the API to the process engine.
Hi @StephenOTT
the docker containers use the default Camunda distribution settings, so the job executor is configured to be deployment aware.
If you deploy processes through the REST API you cannot use this setting as already mentioned by @thorben:
This is not related to the docker images.
Or if I misunderstood your setup or deployment procedure please tell me how I can reproduce this behavior.
Cheers,
Sebastian
@menski I do not think this is related “specifically” to the docker image. But i guess possible.
Based on @thorben’s comments above, and the documentation about DeploymentAware (which is on by default).
The steps to reproduce:
- Deploy default docker container setup.
- Deploy a BPMN with a few automated tasks such as a script task. Make the Start event, and all tasks async.
- Run the BPMN.
- Stop the Container
- Start the Container
- Run the BPMN
On the second run of the BPMN, the behaviour we are seeing is that the process will get stuck on the start event and not move forward - the job executor is not running for that process deployment anymore. If you redeploy the BPMN, the problem is resolved. It looks like the DeploymentAware / The details that @thorben describe here:
are not occurring.
How do you deploy the process? As process application (war), by Java Code or with the REST API?
1 Like
Bad news - this problem is occurring again.
Back in August, as suggested by thorben, we deactivated the deploymentAware setting. The current setting in our bpm-platform.xml is: <property name="jobExecutorDeploymentAware">false</property>
For several months, we have not had any problems. However just recently the same problem we originally reported is occurring again. Previously, if we deployed a new version of the model that was getting hung, subsequent instances would run fine. Now however, deploying a new version does not clear up the problem.
So far, we can not find a pattern to the problem. When we bring up a new server, it seems that things run fine for a while, but then suddenly the workflow model in question will no longer execute the async service task. Once we get in this state, it seems the only way to resolve it is to tear down the server and bring up a new one.
To demonstrate the problem I have created a modified version of the Camunda http-connector example. I have uploaded this model. invokeRestService.src.bpmn (11.7 KB)
Also, here is the ACT_RU_JOB table entry for one of the stuck instances:
# ID_, REV_, TYPE_, LOCK_EXP_TIME_, LOCK_OWNER_, EXCLUSIVE_, EXECUTION_ID_, PROCESS_INSTANCE_ID_, PROCESS_DEF_ID_, PROCESS_DEF_KEY_, RETRIES_, EXCEPTION_STACK_ID_, EXCEPTION_MSG_, DUEDATE_, REPEAT_, HANDLER_TYPE_, HANDLER_CFG_, DEPLOYMENT_ID_, SUSPENSION_STATE_, JOB_DEF_ID_, PRIORITY_, SEQUENCE_COUNTER_, TENANT_ID_
'cef61540-be55-11e6-ba32-0242ac120003', '1', 'message', NULL, NULL, '0', 'cef5ee2e-be55-11e6-ba32-0242ac120003', 'cef5c717-be55-11e6-ba32-0242ac120003', '559c8fbd-be55-11e6-b2b3-0242ac120003', '_c2ab1f62-ecd4-4401-96c2-0f67552b1b2a', '3', NULL, NULL, NULL, NULL, 'async-continuation', 'transition-create-scope', '558fe58b-be55-11e6-b2b3-0242ac120003', '1', '559c8fbe-be55-11e6-b2b3-0242ac120003', '0', '1', '7d48ec6a-2144-4535-b54c-2c23e703f3e1'
Here is a screen shot of the cockpit showing instances stuck on the service task:
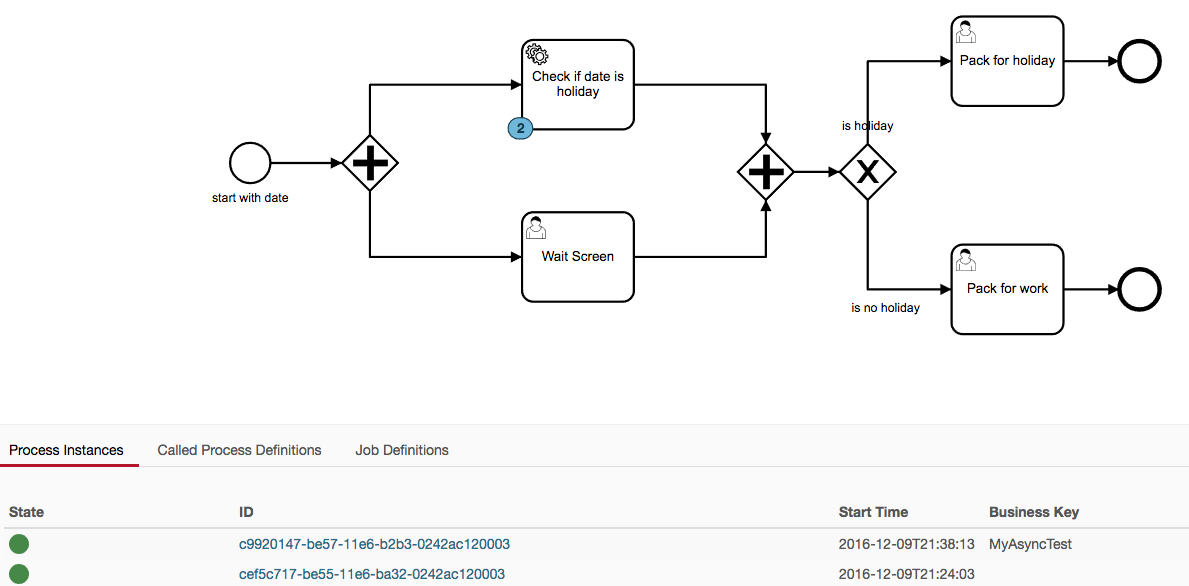
Note one item I did not previously mention, we are deploying the docker versions of the Camunda engine, but with our modifications to bpm-platform.xml. Otherwise, our environment is the same as reported previously in this thread.
Please let me know what additional information I can provide to help solve this issue. Any suggestions for other things we should investigate would be helpful.
1 Like
We believe we have found the cause of this most recent occurrence of this issue.
We discovered that a workflow had been deployed with a problem that seemed to cause the issue. This workflow contained an async script (javascript) task that contained an infinite loop. When an instance of this workflow was running, we saw a significant spike in CPU usage for the Camunda java application. It seems that this script task was constantly running. We think this may have prevented any other async jobs from running. Once we deleted all running instances of this workflow, everything returned to normal: CPU usage returned to normal and other workflow with async tasks ran as expected.
As of now, we are not experiencing the originally reported issue.
Is there such a thing as a max script / task / etc execution timelimit in Camunda?
Note that we tried putting a BPMN timer event on the script task, such that it cancelled the task after a minute and then continued on to end the workflow. We observed that while the script task was running there was a significant increase in CPU utilization for the Java process (up to 200%). But even after the task was cancelled and the process instance terminated, the CPU utilization never returned to a reasonable value. I have no idea why that would be.
Hi guys,
Jobs are executed by a thread pool (of limited size by default). Build an infinite loop and you block those threads. The process engine never interrupts/kills running threads. That is also not how timer events in Camunda work. Interrupting events never immediately interrupt other transactions (how should that even work in a single JVM or in a cluster?), but parallel transactions that are in conflict with each other are resolved via optimistic locking. That requires both engine commands to terminate.
Cheers,
Thorben
Thorben,
Thank you for the explanation. This helps to understand what is going on.
Hey @thorben I am circling back to this, and have some follow-ups:
You mentioned here:
-
That you can disable deploymentAware or register manually. If this is the case, when a shared engine is being used, is it typical to have deploymentAware disabled as a default?
-
What is the reasoning for deploymentAware to be enabled on the default camunda configuration?
-
How are camunda server restarts handled based on the default configuration? Based on the docs, and your comments above, the default settings would assume that if you have a async process, and you restart your server, then you must manually register the deployment? If yes, referring back to #2 above, why would this be the default behaviour of the engine?
Thanks!
Hi Stephen,
- If your processes depend on process application resources, you should not disable
deploymentAware. If your process deployments are self-contained (e.g. only script tasks), it should be fine to do so. - This follows from the first answer. Developing process applications is the most frequent use case. Activating
deploymentAwarein the distributions by default avoids seeing class loading exceptions when using process applications. Especially as a getting started experience this would be awful. - If you have process applications, the engine recognizes the process applications automatically and makes registrations. If you don’t have process applications (or undeployed a process application but still want to execute jobs), then you must do manual registration in a
deploymentAwaresetting.
Cheers,
Thorben
@thorben what are your thoughts on making this env variable changeable? Default/if env is not provided then it defaults to current. Otherwise you can provide a env for this? (at least in the docker container)
Feel free to propose this for the docker container. I don’t really see the necessity to have this as a general engine/platform feature right now.
Fair enough 
@thorben, would it be valid to say that anyone using the engine in a Shared Engine environment, and is using deployments through the REST API, should have deploymentAware set to False?
Yes, I think that’s a good rule.
@thorben I do not believe this “rule” is documented.
This seems to me to be a important “rule” to be aware of for REST deployments. https://docs.camunda.org/manual/7.6/user-guide/process-engine/the-job-executor/#job-execution-in-heterogeneous-clusters could have this note added to it.
But where else would you suggest this be added?
1 Like