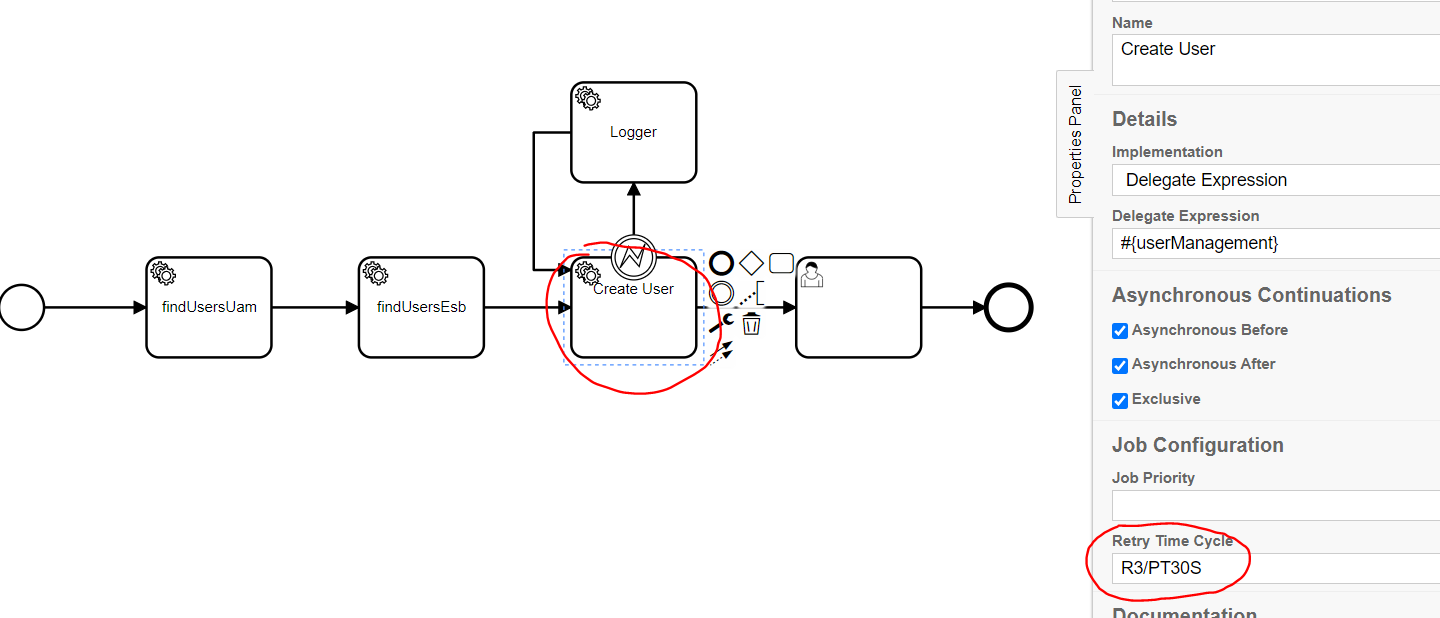
I have a cycle configuration but it does not work. When the bpmn exception is throw, I expected that Camunda will wait for the interval and try again but it does not happen.
@Component
@Slf4j
public class UserManagement implements JavaDelegate {
@Override
public void execute(DelegateExecution delegateExecution) throws InterruptedException {
String userUamId = (String) delegateExecution.getVariable("userUamId");
String userEsbId = (String) delegateExecution.getVariable("userEsbId");
log.info("Uam ID {} and user Esb ID {}", userUamId, userEsbId);
throw new BpmnError("FatalError");
}
}
How you can see, the difference between the logs are of the miliseconds
*2021-09-28 10:32:02,318* INFO [55cf6c01d7cbef8e] s.j.m.s.c.c.processor.UserManagement |- Uam ID 5 and user Esb ID null
*2021-09-28 10:32:02,398* INFO [55cf6c01d7cbef8e] s.j.m.s.c.c.processor.LoggerDelegate |- LoggerDelegate ....
*2021-09-28 10:32:02,435* INFO [55cf6c01d7cbef8e] s.j.m.s.c.c.processor.UserManagement |- Uam ID 5 and user Esb ID null
Sorry, I didn´t get it, in my process I’ll need to call an API and if I receive a 400 status code, I´ll need to try again in the 30 minutes, How Do I deal with it without throw an bpm exception? How will I say to camunda:
" Hey, how I received an 400 status code, you´ll need to call this task again"
The other solution is to set retry time cycle value, tick async before for the service task and throw a Java exception with the proper error message in your implementation in case of failure. (This way camunda will do the retry job as per the configured value for “retry time cycle” and once all retries get consumed an incident will be created so using cockpit, an admin can view the exception message and take the required action manually)
If you don’t want to throw a Java exception then you can proceed with your solution which is to model the error but you have to use a timer in your model to let execution token waits for the specified period before returning to the same service task. (retry strategy wouldn’t work in this case)
A total of 3 automatic retries to be consumed.
Each retry to be started every 30 seconds.
Once all consumed with no success then an incident to be created.