Hey everyone
so use case came up recently for doing some web scraping with Camunda. From this we needed more powerful features from HTTP requests and so we loaded http://jsoup.org into camunda int eh shared engine.
From this we realized that this was actually a much more flexible solution compared to using HTTP-connector.
Jsoup is optimized for html/xml responses, but with a few tweaks to the configurations of a request (all standard/supported by Jsoup), we end up with a great JSON or “whatever” http request manager for requests and responses.
It also has many fixes for other problems with http-connect such as timeouts, attachments/binary data, buffer streams, and response time, etc. (many of which have been discussed in detail throughout the forum).
So what did we end up with!:
First we added Jsoup to Camunda. We put together a docker compose for you to make this as easy as possible:
Specifically: https://github.com/DigitalState/camunda-variations/tree/master/web-scrape
This will load camunda 7.7 tomcat with deployment-aware = false and add Jsoup to the classpath
Next:
In our case we use Javascript/nashorn for our scripting
So you can easily access Jsoup through Java or just through the script engine:
Javascript:
with (new JavaImporter(org.jsoup))
{
// var body = {
// "myKey1": "myValue1",
// "myKey2": "myValue2",
// "myKey3": {
// "internal1":"internalV1",
// "internal2":"internalV2"
// },
// "myKey4": [
// 1,2,3,4,5
// ]
// }
var doc = Jsoup.connect('http://date.jsontest.com')
.method(Java.type('org.jsoup.Connection.Method').GET)
// .method(Java.type('org.jsoup.Connection.Method').POST)
.header('Accept', 'application/json')
.header('Content-Type', 'application/json')
// .data('filterABC', 'subgroup1')
// .requestBody(JSON.stringify(body))
.timeout(30000)
.ignoreContentType(true) // This is used because Jsoup "approved" content-types parsing is enabled by default by Jsoup
.execute()
var resBody = doc.body()
var resStatusCode = doc.statusCode()
var resStatusMessage = doc.statusMessage()
var resContentType = doc.contentType()
var resCharSet = doc.charset()
}
function spinify(body)
{
var parsed = JSON.parse(body)
var stringified = JSON.stringify(parsed)
var spin = S(stringified)
return spin
}
execution.setVariable('responseBodyString', spinify(resBody))
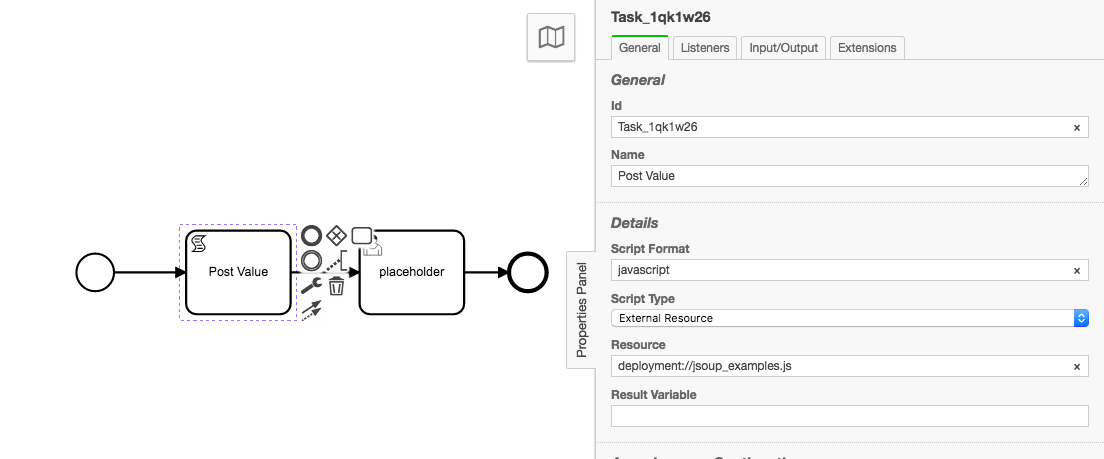
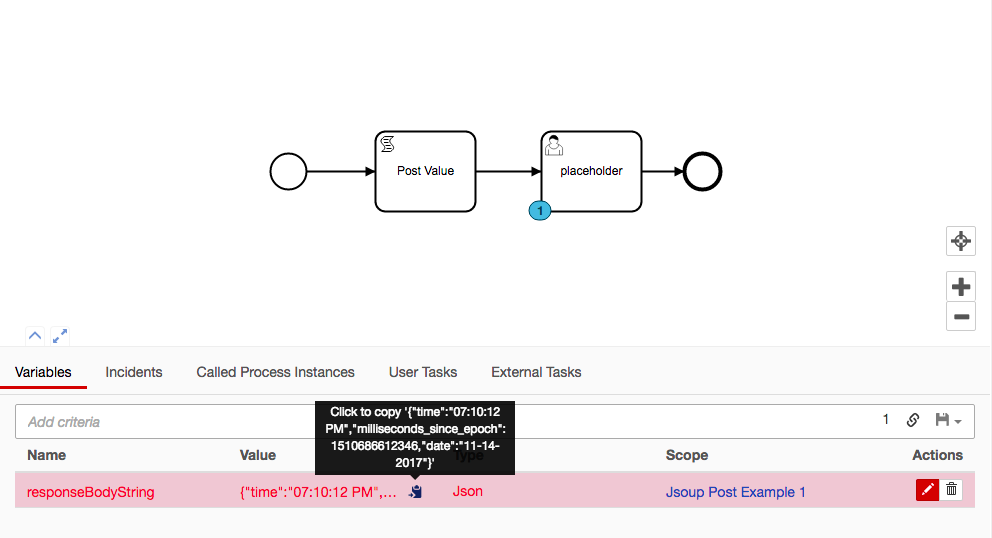
If you take a look through the Jsoup JavaDocs there are tons of options to customize the exact request and response you wish to work with. And you can easily replicate HTTP-connectors Input/Output abilities with some JS functions that look for Input parameters on the task.
See: Nashorn extensions - Nashorn extensions - OpenJDK Wiki for further details about all the ways you can import packages and classes with Nashorn. In this case we are using the with() method that allows us to encapsulate the package in its own scope and not pollute the global scope.
The one item that would be great from @camunda is the ability to execute scripts as part of Service Tasks, Send Tasks, and Throw Message Events so that the BPMN does not have to be script tasks everywhere (or not having to use Execution events / input/output parameters).
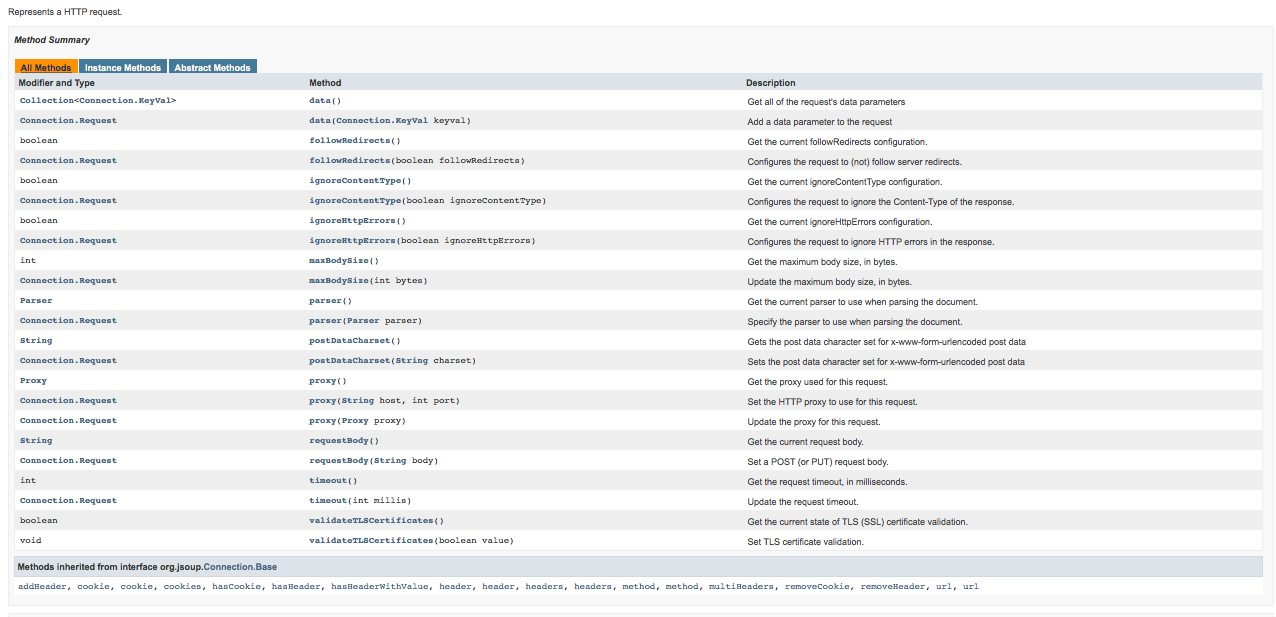
Some quick examples of really useful methods from Jsoup:
Requests:
Responses:
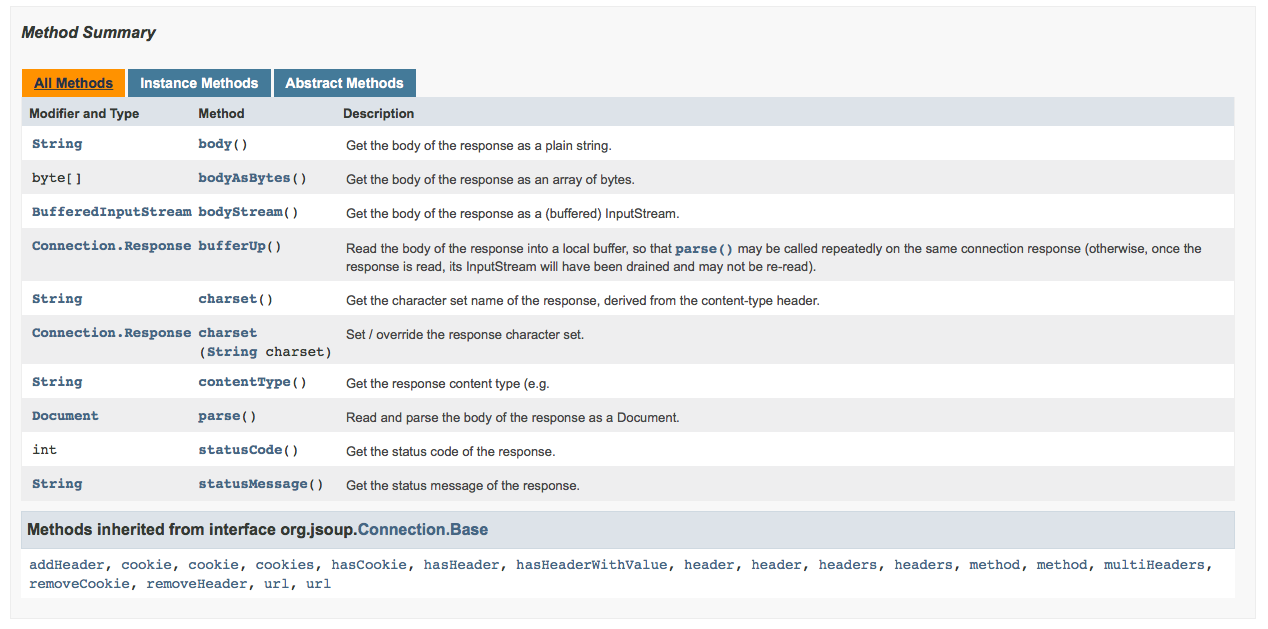
A few notes on reasons for things:
- the
spinifymethod is used because in order to properly stingify the json response we need to parse it, otherwise the stringify will add/ncharacters for pretty printed json responses ignoreContentType()is used int he.connect()method because Jsoup does a pre-parsing content type validation check that looks for the pre-approve content types that Jsoup is optimized for (text, html, xhtml, xml, etc (HTML related content types))- The
.execute()method is used instead ofget(),post(), etc because theexecute()method does not parse the response for html. - Take a look at the many different ways to create headers and data. Maps are supported, query params, Form Data, etc
- Note the enum usage in the
.method()line. The enums are a specific type and because JS is typeless you need to force the type withJava.type(). See the Nashorn extensions - Nashorn extensions - OpenJDK Wiki docs for more info. - Another great benefit is that Jsoup provides much more robust errors/exceptions that provide better
Catch()capabilities and just general debugging.
Would love to hear anyones thoughts on this approach. So far our testing is showing very fast execution times and other than a patterns to develop (such as the spinify() method, and the usage of ignoreContentType() in the code sample above), everything “just works” as one would expect with a HTTP request DSL.
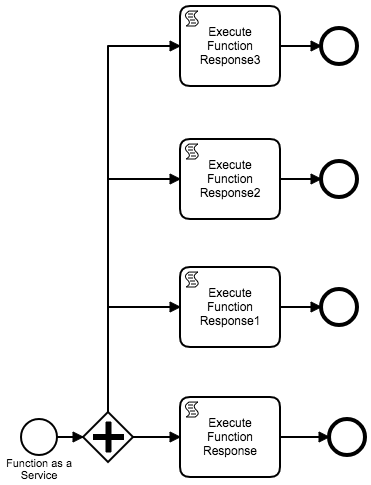
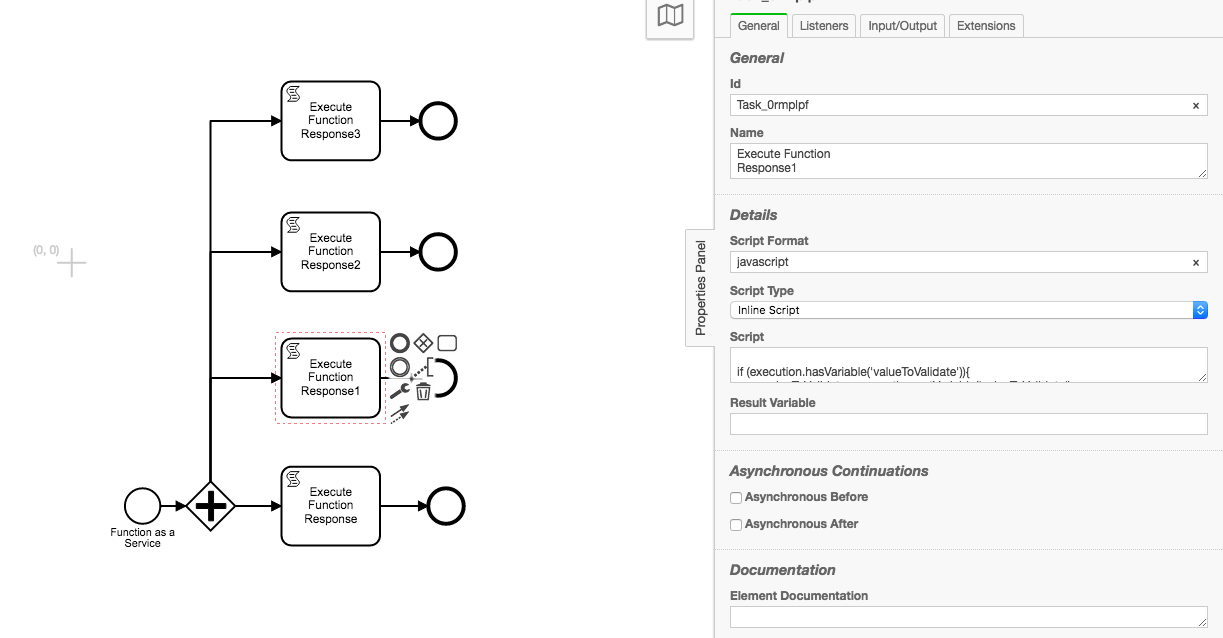



 If you need only simple API call from scripting task, you may reach that by calling internal HTTP connector as shown below. In this case you do not have to add any library to classpath.
If you need only simple API call from scripting task, you may reach that by calling internal HTTP connector as shown below. In this case you do not have to add any library to classpath.