In a Springboot app, I’m currently working on I’ve got a sender and receiver task.
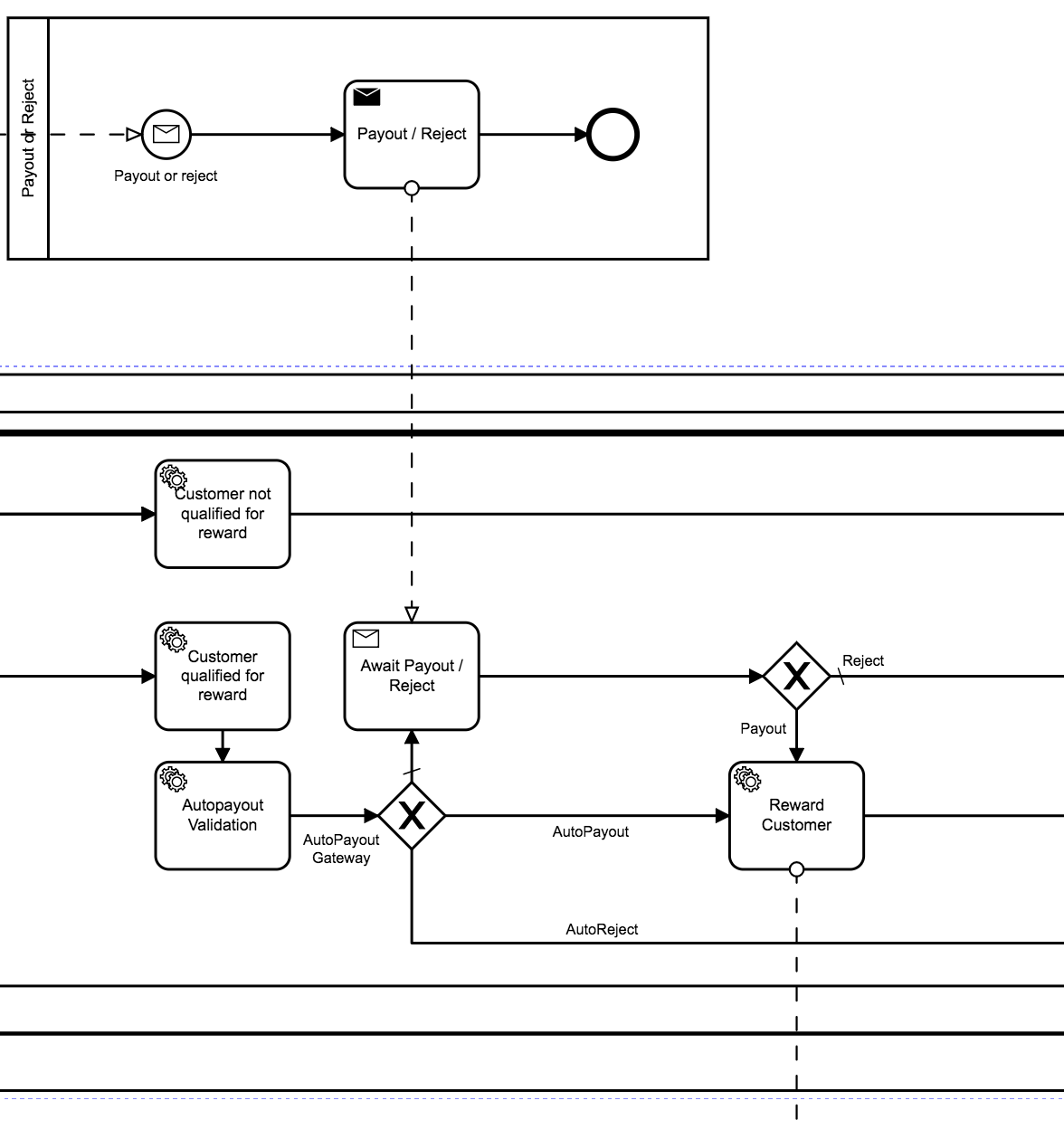
A swin lane sending a correlate all message and another swin land receiving the message and triggering, in this case, payout action, see below.
There are 10k instances waiting and correlated against a single process variable.
Note 1 it is not possible to correlate against the businessKey as this is upstream in the process.
Note 2 I’ve also set jobExecutorActivate to true / active.
Four instances are depoyed in AWS, with an RDS postgres DB.
When the correlateAll message is received, only one instance, of the four, processes the request to latch the 10k processes, last diagram below.
runtimeService
.createMessageCorrelation("Payout_Action_Event")
.processInstanceVariablesEqual(new HashMap<String, Object>() {{
put("correlateName", "correlateValue");
}})
.correlateAll();
Give the correlation occurs against a single variable, is it possible to distribute the processing across the four instances? Asynchronous handling?
Process snippet
Receive task
Blue line the instance that sent the correlation and receives.
1 Like
Very interesting use case!
The correlation seems to be doing what it is doing because its a single thread that is executing the correlation request and therefore its just 1 instances that does the correlation!
Assuming there is not a api i am missing that would allow you do do some fancy job processing,
You could do the following:
Create a message query to find all process instances that match your variable query. This will create a array of process instances that you want to correlate against.
Then you can pass that array/collection into a Parallel-Multi-Instance Send Task, and have the multi-instance set as Async Before. This will generate a single job for each of the process instances that you want to correlate against.
Then the job executors from the cluster will pick up on those jobs and start processing in parallel and across all of the nodes.
edit: You might also want to batch the jobs together in say groups of 100, or whatever. This way you dont have overhead of creating Jobs in the DB for just a single process correlation.
Would be very interested to see some performance graphs on this!
2 Likes
Thanks for the suggestion @StephenOTT, I can certainly try this approach, although wary of the message query cost. Worth a try though I’ll update the forum on my findings for this case.
Why are you worried about the message query cost? You are having to perform this query no matter what. If you did a correlation and it was magically doing is across the cluster, you are still having each node perform the query.
Hi @StephenOTT, I based this somewhat on the blog post https://blog.camunda.com/post/2014/03/fluent-api-for-message-correlation/.
And the correlateAll performing in a group vs individual correlations, similar to batch vs singles.
Again this was my assumption, I have not examined the camunda code.
The lack of efficiency outlined on that blog post is: more lines of code, and running two commands rather than one. In your use case you are subject to both of these as you want to distribute the correlation command across the cluster. Thus you turn your command into a series of jobs and distribute the jobs.
This is the interesting part: will it be faster to create batch jobs of N instances to correlate against, or have the single node perform the job.
To distribute the job you have to generate all of the sub jobs and have the cluster node pick them up, so you are paying a penalty for choosing to do that. BUT it might be faster under larger loads
Hi @StephenOTT
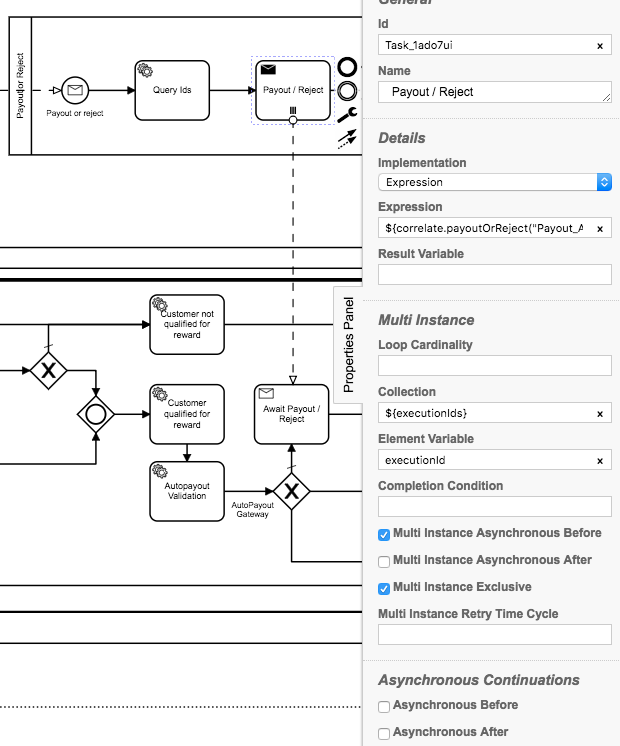
I set up a parallel multi instance send task with, with mult instance async before checked. This is sent a list of ids. Note I also checked the async before when multi instance didn’t work.
However I’m still seeing only one instance pick up the jobs.
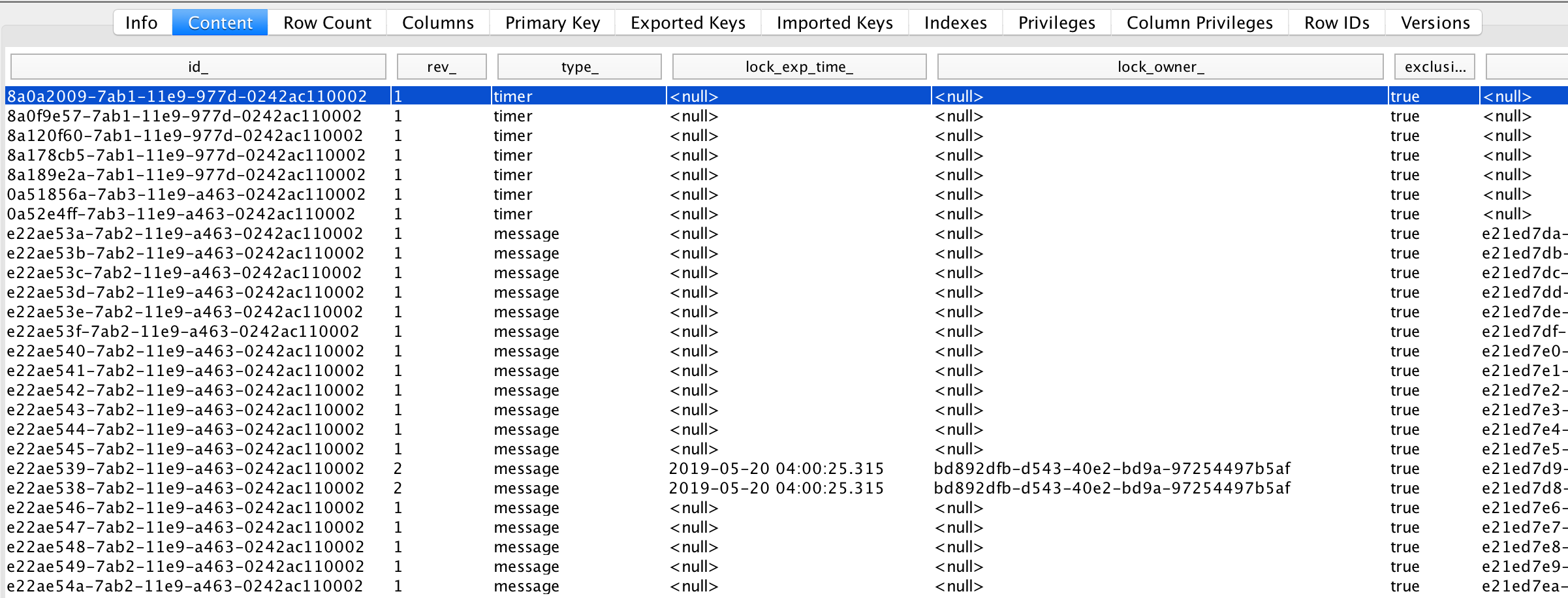
I checked the ACT_RU_JOB table, and the jobs are created!
History is disabled, and engine properties the defaults.
Set up as follows
Note it appears as follows in the cock pit.
The springboot app has an enabled executor.
As follows;
processEngine.getProcessEngineConfiguration().setJobExecutorActivate(true);
Also tried within the following configuration in app.yaml
camunda.bpm:
job-execution:
enabled: true
max-pool-size: 15
core-pool-size: 15
keep-alive-seconds: 10000
The send task is calling an expression which is wired to
public void payoutOrReject(String msgCorrelation, String executionId, String varName, String variable) {
runtimeService.messageEventReceived(msgCorrelation,
executionId,
new HashMap<String, Object>() {{
put(varName, variable);
}});
}
This is the only async continuation in these flows.
Any ideas?
Is it possible the other nodes are attempting to acquire the same jobs and backing off? Leading to only one node processing?
ACT_RU_JOB table looks as follows during a run…
Regards
Tom.
How are you deploying? Do you know about the “deploymentAware” setting?
Also when you are deploying multiple nodes, they are all using the same engine name?
As a quick test run your two node and create the jobs and then kill node 1 and see if node two picks them up
The workflow is embedded within a Spring boot app.
Thus never a deploy, of a workflow or DMN, into the app, note however the deploymentAware is true.
The apps are deployed as a homogeneous cluster, as per docs - https://docs.camunda.org/manual/latest/user-guide/process-engine/the-job-executor/#cluster-setups.
I’ve left the Process Engine Name as ‘default’.
I’ve update the app.yml config to
camunda:
bpm:
job-execution:
enabled: true
deployment-aware: true
max-pool-size: 15
core-pool-size: 15
keep-alive-seconds: 10000
Which I see in the logs
2019-05-21 13:46:02.966 INFO 6519 --- [ main] org.camunda.bpm.spring.boot : STARTER-SB040 Setting up jobExecutor with corePoolSize=15, maxPoolSize:15
Note I’ve observed, the logs across the cluster as
2019-05-21 12:33:03.691 INFO 5877 --- [ main] org.camunda.bpm.engine.jobexecutor : ENGINE-14014 Starting up the JobExecutor[org.camunda.bpm.engine.spring.components.jobexecutor.SpringJobExecutor].
2019-05-21 12:33:03.695 INFO 5877 --- [ingJobExecutor]] org.camunda.bpm.engine.jobexecutor : ENGINE-14018 JobExecutor[org.camunda.bpm.engine.spring.components.jobexecutor.SpringJobExecutor] starting to acquire jobs
As per suggestion when I killed an instance, processing the jobs, the second node didn’t pickup the processing.
Do you know of any Camunda Spring Boot examples using a similar approach?
I’m at a loss to understand why it’s not working.
So set your deploymentaware to false and retry.
@tomconnolly did the above resolve your issue?
Hi @StephenOTT, it did but with some caveats.
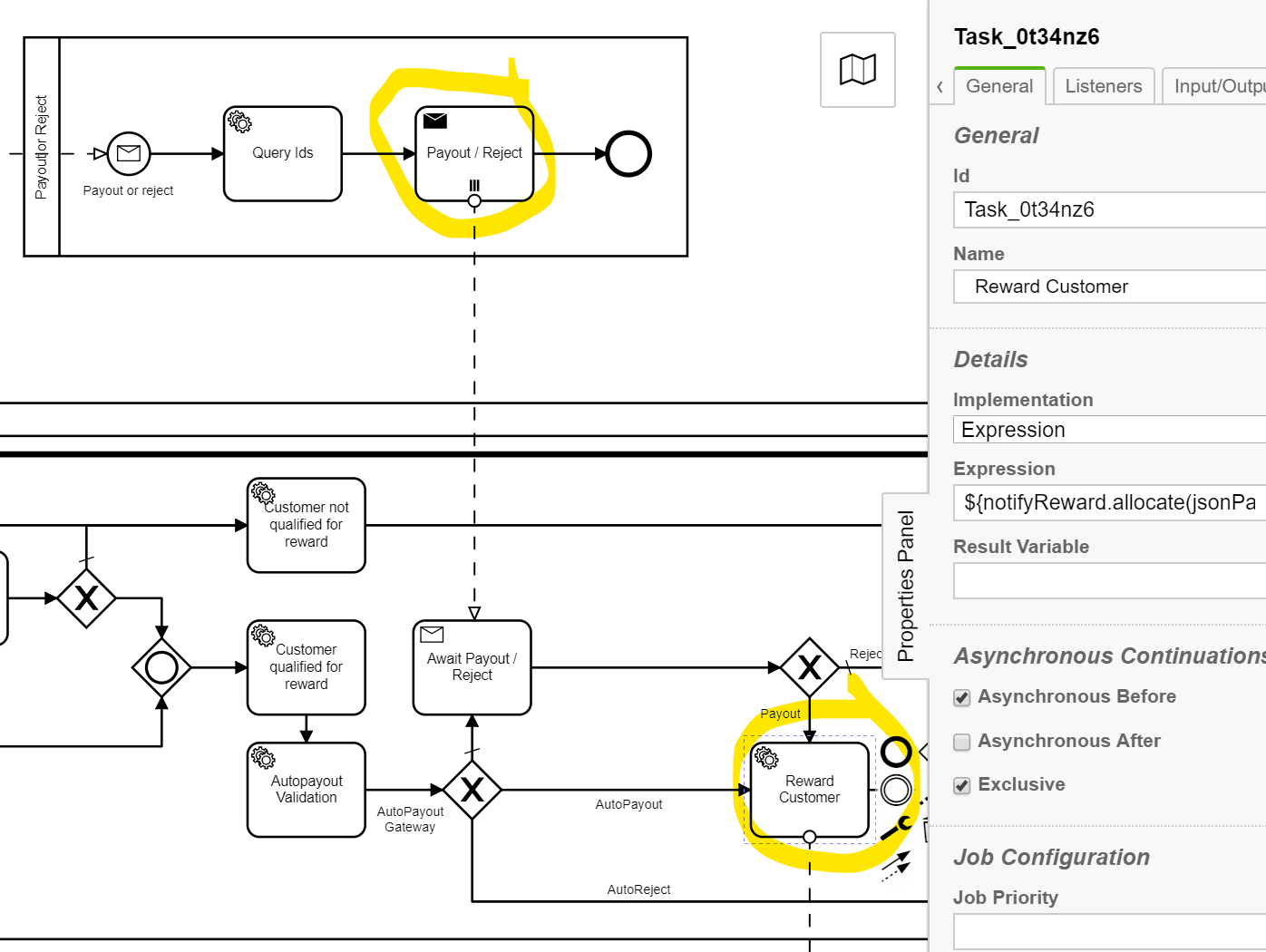
The async before on the send task only acts on the instance that initiated it, open to suggestions, as to why.
However I was able to use an async before on a downstream service task, ‘Reward Customer’, which did distribute the jobs across the instances, see example following.
I did, as you suggested, batch up the jobs which provided a major improvement over individual messages.
@Service("correlate")
public class Correlate {
@Autowired
private RuntimeService runtimeService;
/**
* Return a list of byte arrays corresponding to offers waiting reject / payout
* Note using byte array as strings have an upper limit of 4000 characters
*/
public List<byte[]> getProcessExecutions(String msgCorrelation, String matchName, String matchValue) {
List<Execution> list = runtimeService
.createExecutionQuery()
.messageEventSubscriptionName(msgCorrelation)
.processVariableValueEquals(matchName, matchValue)
.list();
List<String> executionIds = LambdaHelper.convertList(list, Execution::getId);
// Partition into a list of lists
List<List<String>> partitions = Lists.partition(executionIds, 200);
List<byte[]> ret = new ArrayList<>();
for (List<String> partition : partitions) {
String strs = String.join(",", partition);
ret.add(strs.getBytes());
}
return ret;
}
public void payoutOrReject(String msgCorrelation, byte[] executionIds, String varName, String variable) {
String[] list = new String(executionIds).split(",");
for (String executionId : list) {
runtimeService.messageEventReceived(msgCorrelation,
executionId,
new HashMap<String, Object>() {{
put(varName, variable);
}});
}
}
}
Thanks for all the help.
2 Likes