Firstly, I should explain that the vast majority of our work is automating “machine” processes. While Camunda is very flexible, my perception is that the emphasis is on human driven tasks, albeit with a significant portion of that involving some machine-to-machine activity. Our work is attempting to take people out of the process so that we provide more consistent, reliable, and faster resolution of problems. We only want people involved where encoded logic cannot reliably drive the required activities (i.e. fallout management).
We have “workflows” that might contain 10, 20, or 30 steps (activities). At many of these steps, there may be anywhere from 2 to over 100 different “paths” (decisions) that cause it to branch off to a different set of activities based upon current event attributes (process variables). One challenge is deciding when to use BPMN versus DMN versus hand coded (i.e. Java classes) encoding* of workflow logic.
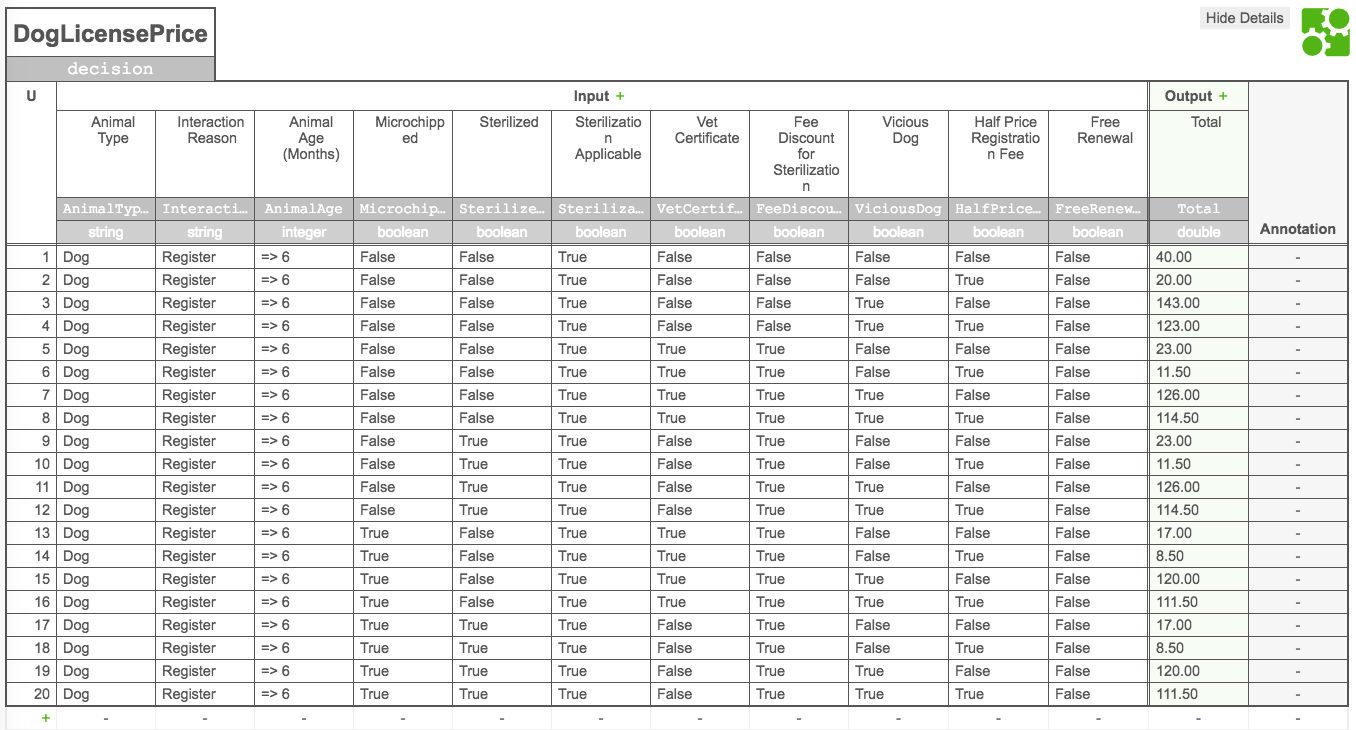
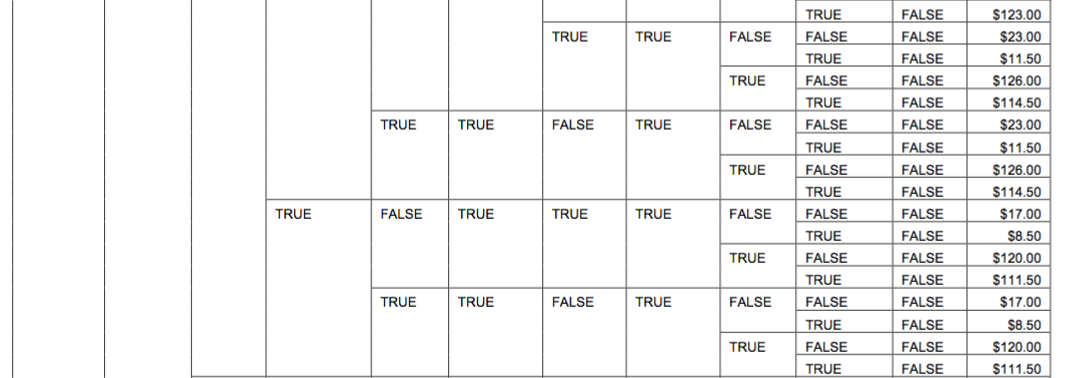
One current system has two attributes that drive workflows. There are approximately 100 different values for each attribute, which means there are as many as 10,000 different paths that can be taken at the first major decision point. After that point, sub workflows may also require evaluation of a large number of attributes (based upon other values passed into the workflow or gathered during its execution). Nonetheless, each “decision point tooling” would be considered using the same guidelines.
For example, we might say that if you come to an activity that provides for multiple execution paths, of which you must choose one, then if the number of possible paths exceeds five (5), you should use a DMN table. Otherwise, you should use BPMN. The reason one use this guideline is that more than five sequence flows off of an exclusive gateway becomes “messy” and diagrams may become too large to manage. Camunda would not care, but again this comes down management of the decisions by people, not machines.
I have decided that the best approach to creating these guidelines is to consider ease of creation and maintenance of the logic for that activity. In the end, we spend little (actually none) time executing workflows. Camunda does that for us. Most of time is spent creating, managing, and analyzing workflows. Therefore, the choice(s) of tool used to encode workflow logic is the most critical decision.
As we are speaking of tools, I poked around the converter code and, to my limited Java experience, seemed relatively straightforward. I think my colleagues who are real Java programmers would be able to modify it to suit a broader range of needs.
One thing it would be good for is “one-off” conversion of rules from other systems. For example, we currently have large database tables which contain rules that accessed by returning rows based upon an SQL query. If the logic of this query were “uniary” (which I think means “does this match”) for several key columns, then translating the table to DMN through the converter would be very easy. More complex logic, again the result of an SQL query, could also be encoded by extending the converter code.
As I mentioned in another post, OpenL Tablets’ implementation of DMN does provide a slightly more sophisticated conversion mechanism, but also lacks the constraints that a dedicated, albeit more general use, DMN tool would impose upon the user.
Congratulations on reaching the end of this long post! Reward yourself with one adult beverage!
- In this context, encoding means how you store logic, not necessarily the “language” used to so (I acknowledge that DMN is encoded in XML, but there’s actually nothing preventing you from abstracting the logic it applies to reach decisions in a database for example.).