Hi,
We have deployed camunda to a clustered environment in AWS. Our cluster has 3 ec2 instances with camunda on tomcat and we are using default job executor settings.
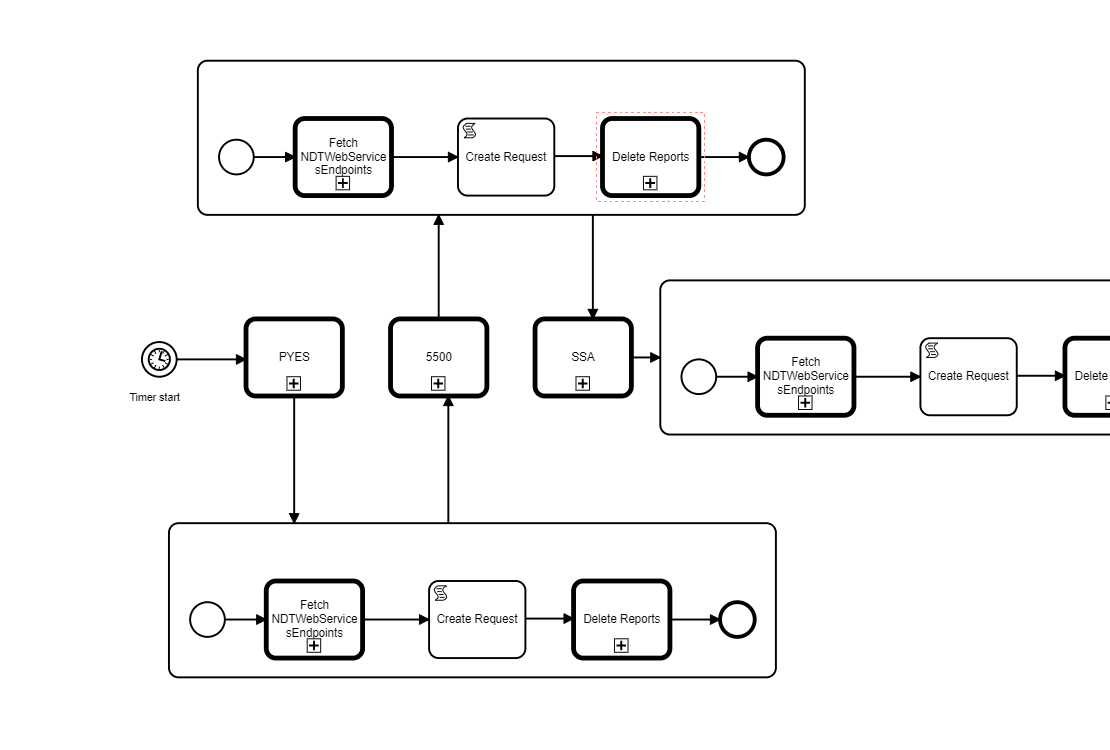
We have models with nested call activities each of call activities calling few APIs through http connector service task. one such model below where each of PYES, 5500 and SSA are nested call activities again
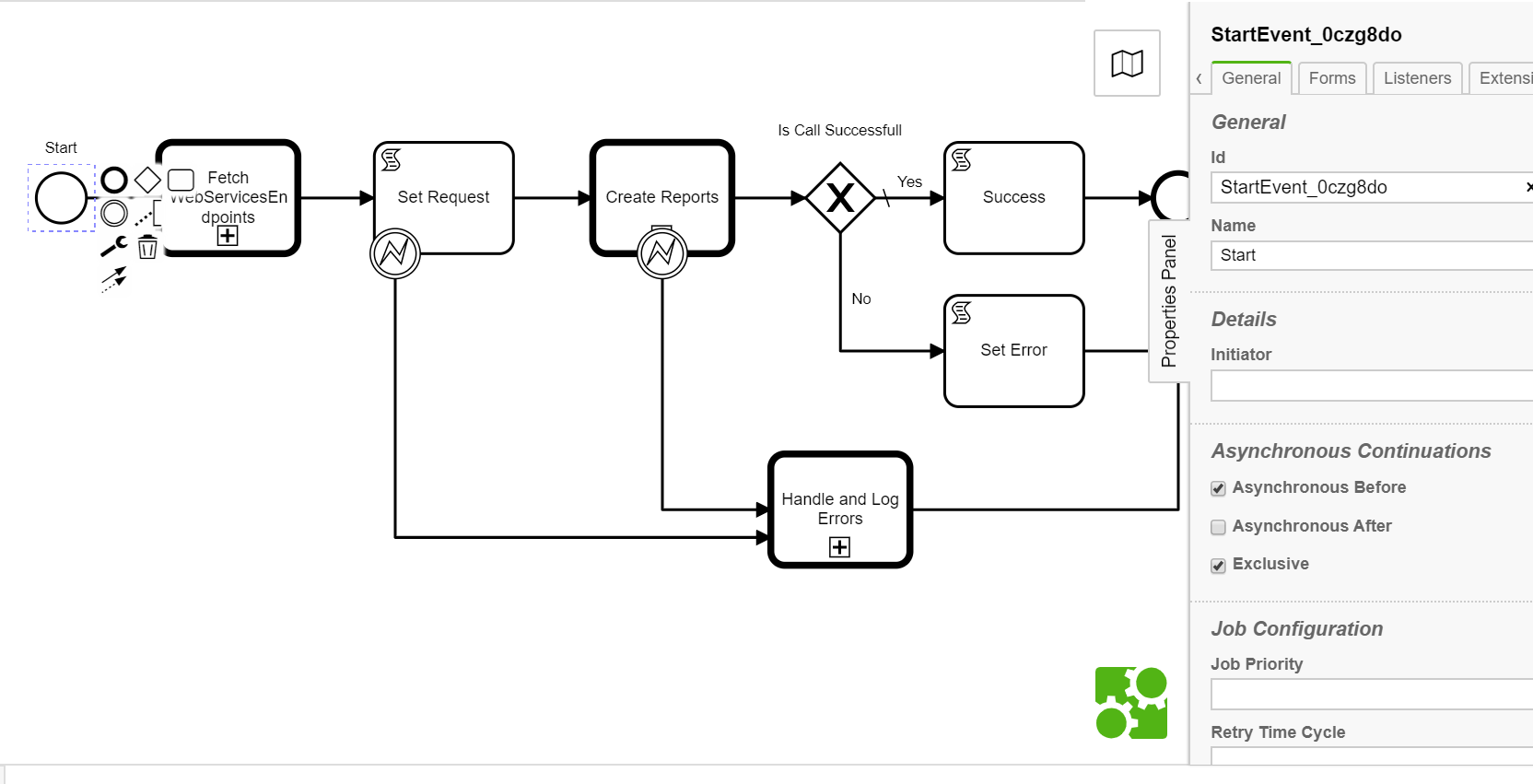
Since these are processes with bunch service tasks with API calls we have put asynchronousBefore on each of the startevent within sub process to break the transaction to avoid timeout settings at our ALB(idle timeout) and tomcat(removeAbandonedTimeout) which are set to 60 seconds. like below
We are seeing performance issues during load Where few thousand main processes are launched, in a cluster only one job executor is executing jobs saved in act_ru_job table and remaining 2 nodes in cluster are idle and eventually none of them ends up picking the jobs. we have default settings at jobexecutor.
Can someone please help understand what is causing the job executors in cluster environment to not aquire job and start executing them. I am also attaching a dump of act_ru_batch table
act_ru_job.csv (105.0 KB)
Hi
Have a look at the docs on clustered deployments. In particular, see if the job executor deployment aware flag is set to false (depends on your architecture eg embedded versus springboot etc…)
In addition, if you are using the connector architecture, by default it used not to time out. hence job executor threads may get blocked waiting on socket connections which never close. Hence consider a custom configuration to set a reasonable timeout…
regards
Rob
Thank you Rob for the response, it appears that we have a lot of HTTP calls and it could be that processes might be blocked and waiting on HTTP response. where and how do I set the timeout for HTTP connector tasks?
Camunda is deployed to separate cluster from application and ee are using tomcat version of camunda and does not have any embedded application, hence we have set deploymentAware flag to false. My understanding is that we will set this to true if we have embedded or other wars deployed with camunda. Correct me if i am wrong
Hi,
can you confirm your deployment architecture?
Do you deploy an application built as a WAR file to a tomcat server?
Do you deploy this WAR file to each tomcat server in the cluster?
Do the tomcat servers all share a common database?
regards
Rob
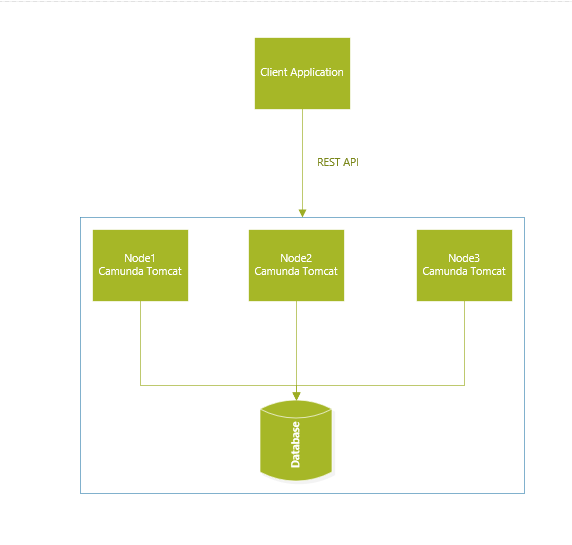
@Webcyberrob here is our simple architecture diagram
Tomcat servers share common database, each nodes have their own tomcat servers. We do not have any application deployed to these tomcat servers, we do have few delegates and plugin jars that we custom wrote deployed to tomcat camunda
Application servers are hosted in their own infrastructure, In short we are not supporting war deployment of models, models are only deployed through rest API
Thanks,
From your architecture description, yes you would need deployment aware to be set to false for the job executors to share the load. How have you configured deploymentAware=false? In addition, are your nodes camunda run or a pre-packed camunda Tomcat deployment?
regards
Rob
Yes I have deploymentAware to be set to false, we are doing a prepacked camunda tomcat deployment.
The problem we face is as we increase loads and as there are more number of jobs to be aquired and executed by job executor.
Hi
Given you are using the pre-packaged Tomcat distribution, can you confirm you set deploymentAware to false in the bpm-platform.xml in the conf directory? (Im still trying to work out why the job executors are not sharing the load…). If thats the case, perhaps you could extract your config, remove any credentials and post here for a followup…
regards
Rob
Hi Rob,
Yes deploymentAware is set to false, here is bpm-platform.xml-
3
5000
60000
300000
50
250
2
3
3
20
0
<process-engine name="default">
<job-acquisition>default</job-acquisition>
<configuration>org.camunda.bpm.engine.impl.cfg.StandaloneProcessEngineConfiguration</configuration>
<datasource>java:jdbc/ProcessEngine</datasource>
<properties>
<!-- History levels: none, activity, audit, full -->
<property name="history">###historyLevel###</property>
<property name="databaseSchemaUpdate">true</property>
<property name="authorizationEnabled">true</property>
<!-- Modified by APS: this setting has been changed because we are not supporing WAR deployment, only model deployent through the REST API. A 'true' value, which is the default, will block asynch processing so it is now set to 'false' -->
<property name="jobExecutorDeploymentAware">false</property>
<!-- If any of below property are turned on, new indexes needs to be added-->
<property name="jobExecutorAcquireByDueDate">false</property>
<property name="jobExecutorPreferTimerJobs">false</property>
<!--Job is retried 3 times after the failure with exponential back off of 1 minute, 2 minute and 5 minutes -->
<!-- <property name="failedJobRetryTimeCycle">PT1M,PT2M,PT5M</property> -->
</properties>
<plugins>
<!-- plugin enabling Process Application event listener support -->
<plugin>
<class>org.camunda.bpm.application.impl.event.ProcessApplicationEventListenerPlugin</class>
</plugin>
<!-- plugin enabling integration of camunda Spin -->
<plugin>
<class>org.camunda.spin.plugin.impl.SpinProcessEnginePlugin</class>
</plugin>
<!-- plugin enabling connect support -->
<plugin>
<class>org.camunda.connect.plugin.impl.ConnectProcessEnginePlugin</class>
</plugin>
</plugins>
</process-engine>
@Webcyberrob Any further recommendations on the above settings?
Hi,
The config file looks correct, so Im still puzzled why the cluster is not sharing the load…This is the same config used on all nodes? The location of this file is in the conf directory?
regards
Rob
In your batch table there are lots of timer records and many errors with connections. Increase connection pool, by setting maxActive to value 100 or more.
Deployment Aware just modify sql query for job executor to find jobs. It is limiting it to some engine with some id. But for example if we using docker compose and doing stop it and then restart we create new docker engine every time. So id is changed, so in docker environment and kubernetis it is recommended to set it false
Yes it is same config across all nodes
DeploymentAware is set to false, the job executor does pick up the jobs initially evenly across the nodes within cluster. it is failing to do so only during load
Hi,
it is failing to do so only during load
Ok - glad to hear deploymentAware is working as expected. I suspect what might be happening is under load, your processes are calling an API. Perhaps this API cant handle load and ends up blocking your connector connections. This can then tie up job executor threads so it appears that he job executor stops working… If you’re using the Camunda connectors, use a config which aggressively times out…
regards
Rob