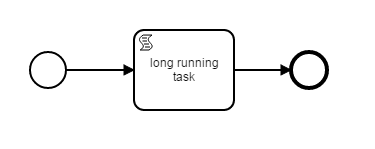
we would like to deploy Camunda BPM as a central orchestration and scheduling component. Our processes are fully automated (no human tasks) and comprise mostly of long running tasks:
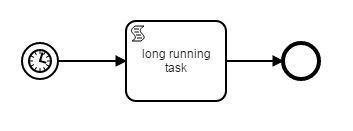
To mimic the behaviour of Windows Scheduler we tried to use Timer Start Events:
Deploying a process definition with timer event leads to creation of a job definition and a job instance (next possible job). Job executor aquires the job and locks it. 5 minutes later it leads to optimistic locking problems resulting in many started instances of the task. We found a workaround for this issue by processing the long running task asynchronously: we start the task and wait in wait state, which is also an intermediate catching event. When the task is completed, we send a message to the catching event.
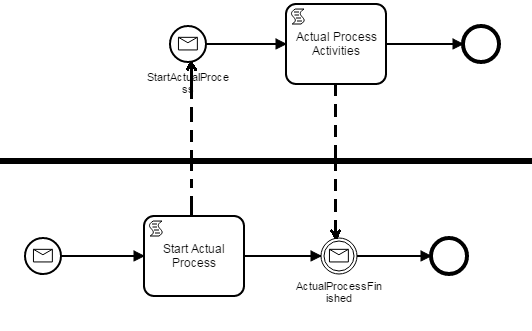
We had some incomprehensive and inconsistent behaviour when we do all this in the same process, so we created two different processes - the first one contains the timer, starts the actual process and waits for it to complete:
One of our requirements was, that the process has to be a singleton - only one process instance should exist at the same time. But another problem with fully automated processes is that they are not persisted, as long as they are running, because we do not have a single wait state and thus the whole process is a single transaction…
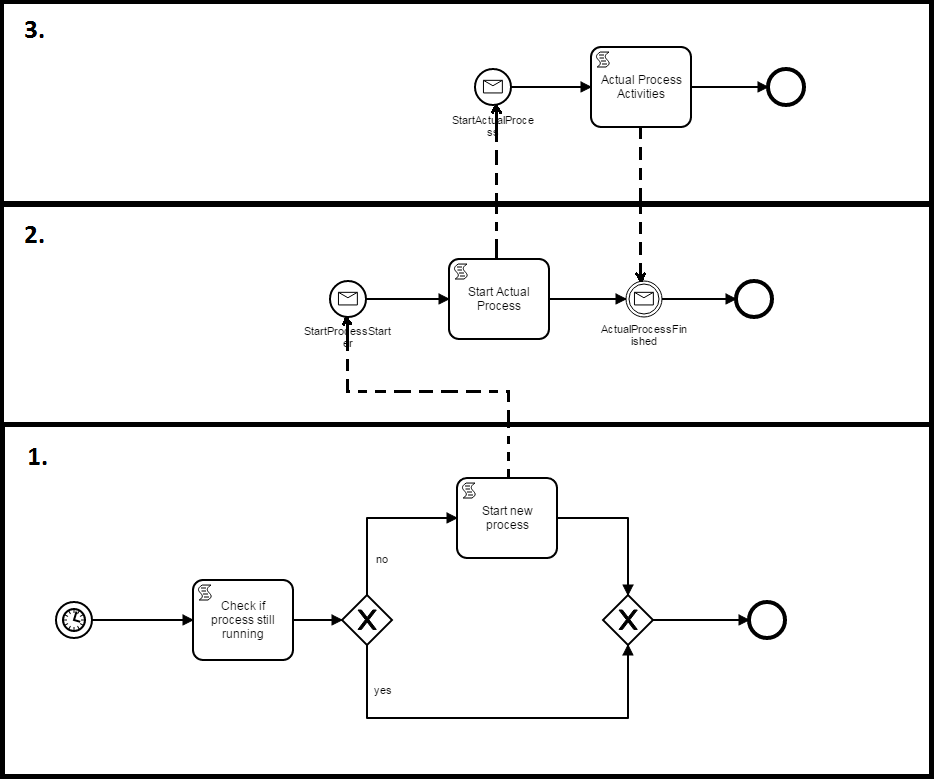
So we looked for another workaround and found following pattern:
We use the process #2 as a proxy. It lives as long the actual process (#3) is running. In process #1 we time-trigger the process and check whether our proxy exists.
Now to my actual question:
Are we missing something? I can’t imagine we need so many workarounds to get our process run as desired. Camunda’s explicit use case is to provide “process automation”. Beeing forced to work only with human and short (<5min) tasks is not what I would call a process automation
Here are technical solutions to the two problems you solved via BPMN:
Long-running automated activities: Do not perform the actual activity in the context of the process engine but outside of it. See external tasks for a convenient way to do this. This reduces the process engine’s responsibility to orchestrating the single steps, instead of also actively performing them. If you really need the engine to do the time-consuming things, then you could increase the job executor’s lock timeout and the transaction timeout.
Single process instance per process definition: As a hard guarantee, this can only be solved at database level. So for example, you could add a unique constraint on ACT_RU_EXECUTION.BUSINESS_KEY_ and set the business key of the process instance to the process definition id. You can find other discussions around this topic in the forum, for example How to Start ProcessInstance idempotently? and Idempotent Start Process Patterns.
External tasks look promising, but I found following statement: “External tasks: Providing a unit of work in a list that can be polled by workers”. This is not exactly the way we want it
Our long-running tasks are mostly python scripts or database procedures (on the same machine). We do not really have/want a listener mechanism here. Is it possible to push the work to the appropriate workers?
Also we do not have a pool of workers, which fetch tasks out of a common list. I’m afraid this is just oversized for our purpose. We don’t really have many tasks running in parallel - they are rather performed sequentially. We need to time-trigger initial process immediately and the subsequent processes should be started dependant on the result of the first one.
What about the lock? Is there a default lock duration or do one have to set it explicitly every time? What do you do if you cant anticipate the the task duration due to natural work load fluctuation?
Not via external tasks unless you build something around the APIs yourself.
The job execution lock time and transaction timeout are global settings. You would have to use the most pessimistic values.
You can also have a look at the asynchronous service task pattern. This would allow you to trigger the operation from Java code (in a push kind of fashion) and then leave the engine context. Once the long-running computation is done, you would trigger the service task again. Note that you will have to handle failures of the long-running computations properly or the service task will never continue, i.e. there is no built-in retry mechanism as with jobs or external tasks.