I have conduct load test on Camunda and tested on different process instance number.
I am calling API to create instance and polling and complete external task.
I have created 30000 instances but Camunda seems not stable and return server 500.
I am using Camunda community and MySQL database.
I have conduct a load test for create 20000 process instances and external task distribution for 20000 process instances last week and here are the result.
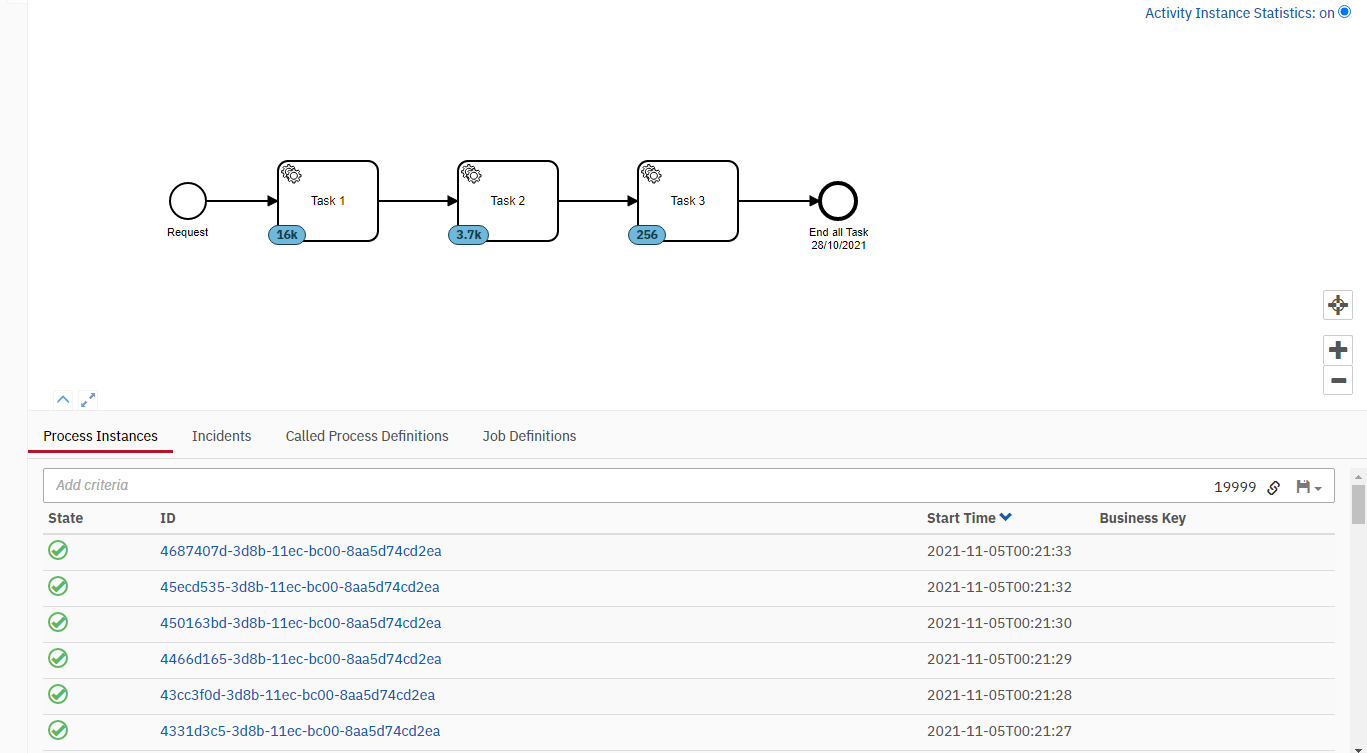
Attached please find our process setup. It have 3 service task call task 1 to 3.
Task A)
Create 20000 process instances (1/s per instance creation by calling api)
Result:
Can create 20000 instances but after that Camunda occurred issue. (Error Log: After create 20000 instance.txt )
Task B)
External Task Distribution( fetch and lock & complete task API ) for 20000 process instances (100ms per api request)
Result:
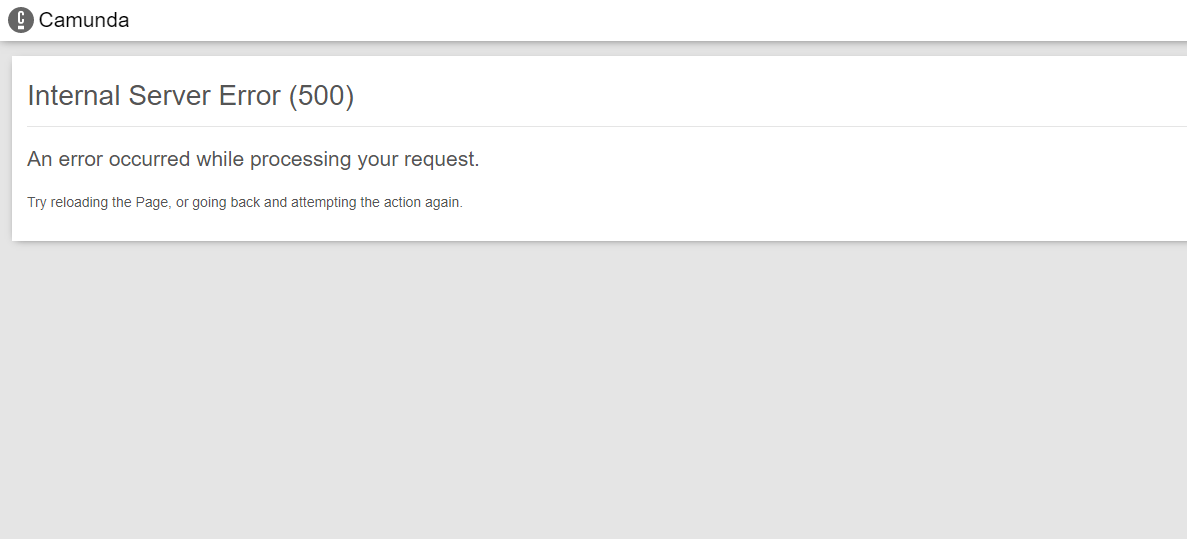
Return status 500 during External Task Distribution and stopped (Please see attached photo)
Task C)
Create 20000 process instances (Multi-threading , at most 64 thread at the same time)
Result:
After create 30000 a few hours, the Camunda server return status 500, cannot call API.
Do you have any info on Camunda stability issue and know the root cause ?
We are using Camunda and Mysql database.
If it have better stability on enterprise version?
Here are some log:
05-Nov-2021 01:23:40.848 SEVERE [http-nio-8080-exec-6] org.camunda.commons.logging.BaseLogger.logError ENGINE-16004 Exception while closing command context: An exception occurred in the persistence layer. Please check the server logs for a detailed message and the entire exception stack trace.
2021-11-05T09:23:40.855185903+08:00 stderr F org.camunda.bpm.engine.ProcessEngineException: An exception occurred in the persistence layer. Please check the server logs for a detailed message and the entire exception stack trace.
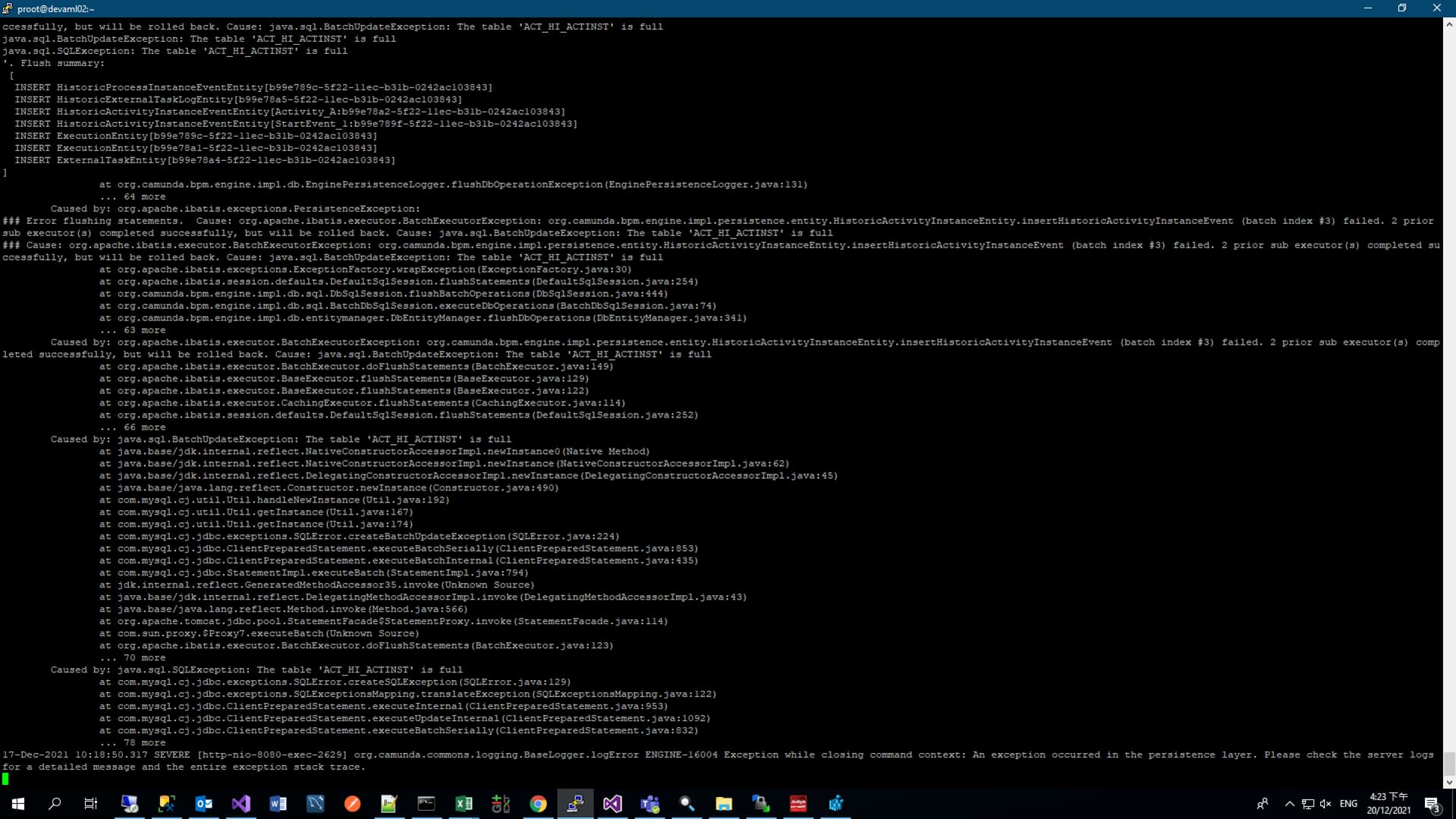
05-Nov-2021 09:43:10.466 WARNING [http-nio-8080-exec-6] org.camunda.commons.logging.BaseLogger.logWarn ENGINE-REST-HTTP500 org.camunda.bpm.engine.OptimisticLockingException: ENGINE-03005 Execution of ‘DELETE ExternalTaskEntity[0013ddef-3d76-11ec-bc00-8aa5d74cd2ea]’ failed. Entity was updated by another transaction concurrently.
2021-11-05T17:43:10.467059640+08:00 stderr F at org.camunda.bpm.engine.impl.db.EnginePersistenceLogger.concurrentUpdateDbEntityException(EnginePersistenceLogger.java:136)
2021-11-05T17:43:10.467059640+08:00 stderr F at org.camunda.bpm.engine.impl.db.entitymanager.DbEntityManager.handleConcurrentModification(DbEntityManager.java:413)
500 Error - It is Optimistic Locking error - Some task already done by another thread. Ordinary this occurs in Lock timeout exipired but worker still do not commit task (due to spam) and other worker locked and already exucuted task + deleted it.
Actually Camunda need to be tuned at diffrents levels to maximize output.
Extrenal task Long polling interval. (better 60 seconds and more)
External task default Lock internal.
External task interval (5 ms is good)
Extrenal task Max tasks (the more spam the more maxTask needed - for my spam test I increased it to 500 to speed up). Also you have to increated db max connection and thread pools because every external task commit required 1 db connection to camunda.
This is the actual logic to run and it has about 20K instance
so, there would have 20000 * 3 external worker working and finally Camunda crash and return status 500.
But we have more than 1000000 instance a year and so we think Camunda is not a stable platform for me.
Thanks for providing this information and asking in our forum. I am trying to understand what your current goal is, do you want to proof that you can run a certain amount of process instances per timeframe? Because what you actually do is stressing the platform as if you need to get high throughput. And depending on how you configure it exactly, you might run into Optimistic lock problems, ddeadlocks or the like. This is generally tunable, and I am confident that you can reach a stable level (see also Camunda Best Practices - Performance Tuning Camunda) - BUT: Do you really need this?
If you need to run 1Mio instances/year, that is less than one instance/minute, which is actually not a high load for us. We run up to 1000 instances/s successfully in some scenarios (with tuning as discussed). So it might be, that you mix up two things: “Can Camunda run 1Mio instances” with “Can Camunda run 1Mio instances in a very short time frame”?
Yesterday I did 8000 instance processes and everything is okay that all task is done.
But after a night long idle , I find it return server status 500 which I think it is very strange.
Do you have any idea on above situation? Stability is very important and the reason we choose Camunda platform but not Camunda cloud is because I need the highest independent(dont want any update/ change of the service).
I have try on Version 7.15, It seem the same result, after all tasks has been successfully fetch and lock, completed all tasks. The platform is going to return 500 error on the next day, think if it have any auto task at mid night?
Find the root cause is the MySQL reconnect issue.
Need to set the reconnect MySQL on yml file when using docker.
mysql://camunda-db-master:3306/camunda?autoReconnect=true
This is fixed and I can go up to 400000 instance now.
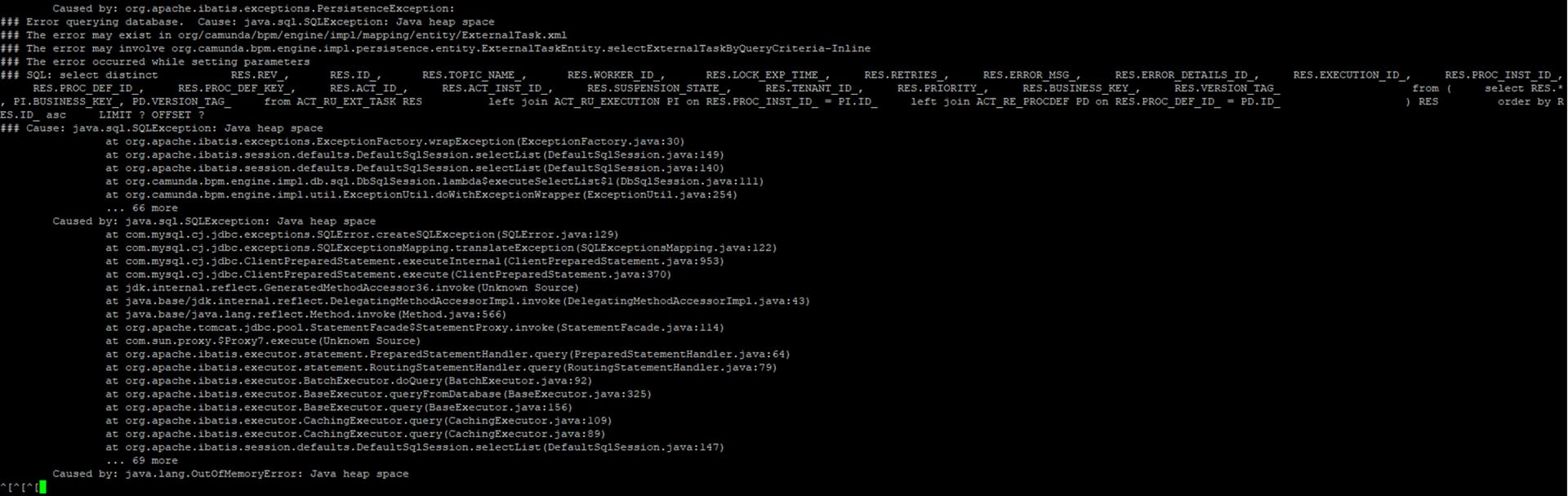
Showing up Java heap space and table ‘ACT_HI_ACTINST’ is full. Do you know how to improve above issue?
Good to see you are a step further @Lawrence! For the heap space: Not an expert myself, sorry, but I guess you can still tune your memory settings (which again might depend on the environment - is it a Spring Boot app? Or …?).
For the table my guess is that you can define max table space settings with MySQL, but again, I am not an expert on this and would need to google around bit (or ask our support ;-)). Fingers crossed!