We are looking to have a process that acts like the following:
- if there is another process with certain variables, append an element to a variable of type list of that process and stop
- if there is not other process which matches, stay in a waiting state until the batch builds up
We implemented this with a exclusive gateway and a delegate which would be executed only in case a matching process exist. The problem we encounter is that if we use a ProcessInstanceModification and we move the process before the “batch activity”, its timer would be resetted and it might never complete.
What’s the appropriate way of building a batch in Camunda?
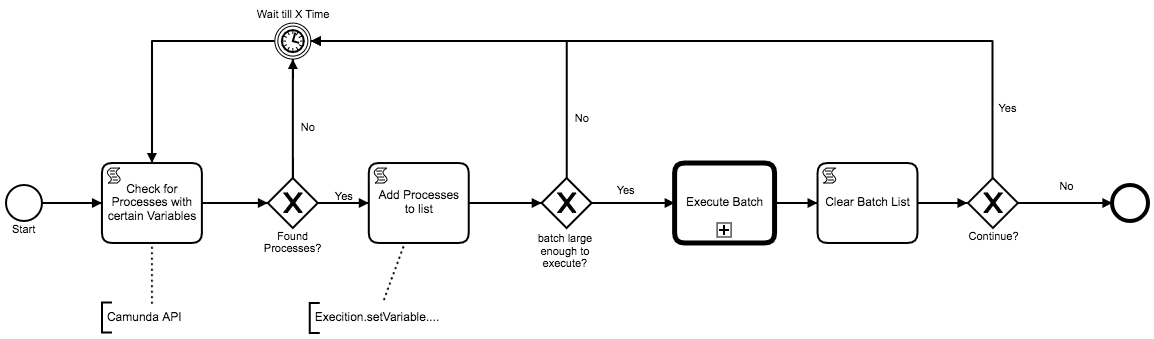
Could you do something like this? (some tasks are shown purely for visual purposes, where they could just as easily be run as script in a sequence flow or listener: such as ‘Clear Batch list’ )
That doesn’t work that well, because our start is triggered by an event. It’s like if three orders are arriving in parallel towards the same street, create a single shipping process.
So if there are no found processes, that process should be the first one and go in wait
ah! Did not mention that. 
So if i am reading this right, you are following the pattern of: The first order becomes the master, and any other orders find a way to attach themselves to the master order?
Could you store the address as a variable and use: https://docs.camunda.org/manual/7.5/reference/rest/process-instance/get-query/ to pattern match based on that address? And then let the original/first order do a check for other orders? Why does the secondary process have to add content to the first process?
Edit: basically if there is a process that already exists (the original order to that address), then you place the second order in a hold state, and let the first process (the original order) do a check at some point to look for extra orders.
That’s all correct. We need to model this way because it’s simply how the business process works for real, orders towards the same address needs to be processed together.
We are using the address variable and we are querying the processes to retrieve which process match the master. The problem is that the process modification API require us to perform a “startBefore” or “startAfter” which would invalidate the time spent in the waiting state.
We would need somehow to add the variables and do not modify the timer
I am saying why do you need the secondary orders to modify variables in the first order? Why can’t the First order do a check for secondary orders? and the secondary orders, when they see there is a first order, they go into a wait mode.
I am not sure I understood, can you explain maybe with a diagram? The secondary orders should “die” and being “cannibalised” by the first one somehow 
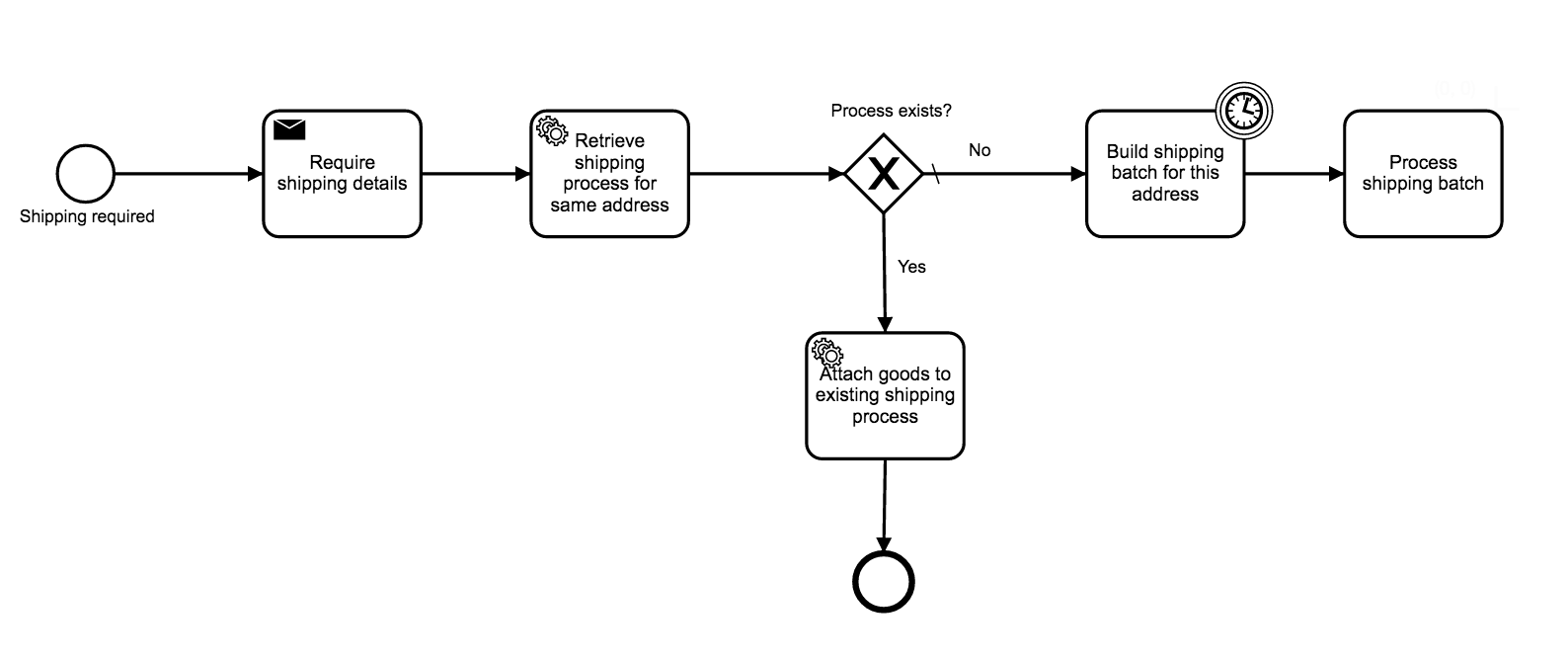
How about something like this? (threw this together, so its missing aspects, but the core ideas ar there… i think).
That seems to work except that we can’t process the order before waiting a batch time and also I do not understand how I would create that subprocess and append the results to a ship order
Are you saying that the master process should retrieve the orders from the other processes and cancel them?
I am saying that the master order should do all the work, and the secondary orders should “detect” that there is already a order started and just wait for a message that the master order has “processed” the secondary order and then close the secondary order.
Let me see if i can clean it up a bit
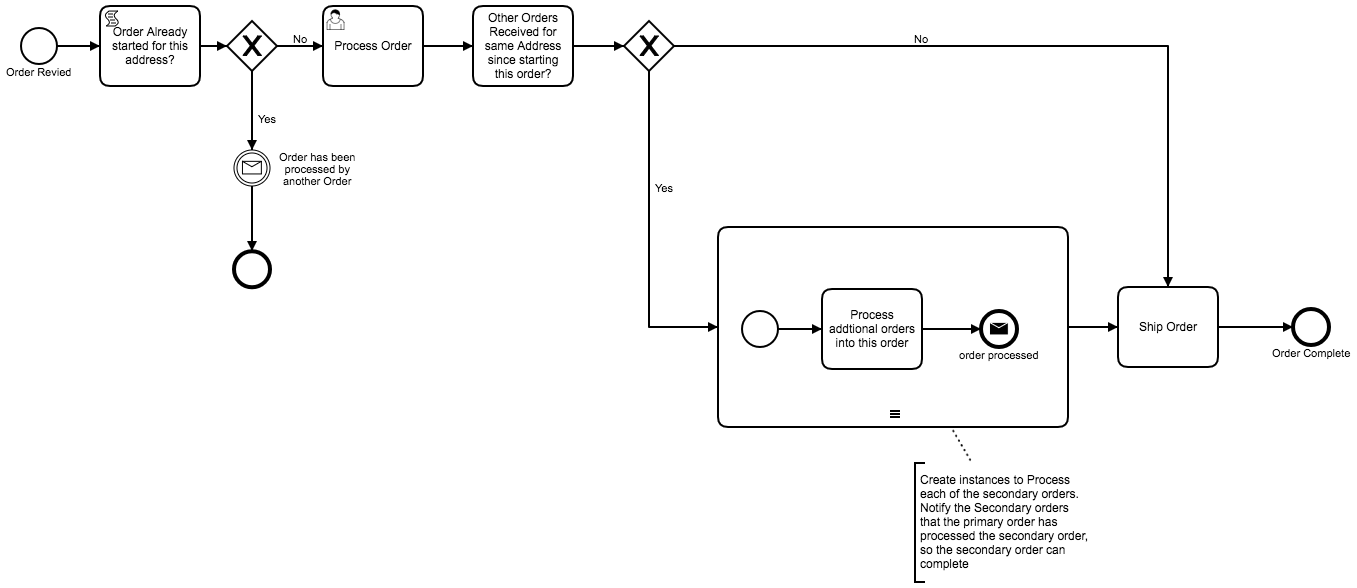
@Edmondo_Porcu how about something like this?
Edit: note that the “order processed” end event in the sub-process is in reference to the secondary order that was managed by the “add secondary order to primary order” script task in the sub-process.
Overview:
-
First order comes in (primary order) and checked if other orders are for the address, the result is “no” so someone/or a system is tasked to preapre the order, as they are prepare the order / start the preperations or complete the preperations, they complete the task and the process checks if there are other processes/orders that were received for the same address since the original order.
-
When the second order is received, the process checks if a address is already being processed, and the result is yes for the second order, so the process waits to receive a message that the secondary order has been processed/added by the primary order.
-
When the primary order executes the check for secondary orders. If you find 3 orders, the sub-process if executed 3 times to add the order details to the primary order. And when the sub-process completes, a message is send back to the secondary order processes to tell them to “complete”/end. So now the primary process/order has all info and you have a full log of what was going on.
-
Once all sub-process/orders have been added to the primary order/process, the primary order is “processed”
So the first order and all subsequent orders for the same address follow the same process
@Edmondo_Porcu does that make sense?
If you provide me with a bit more details about what is a automated and what is a user task that would help to put a example diagram together.
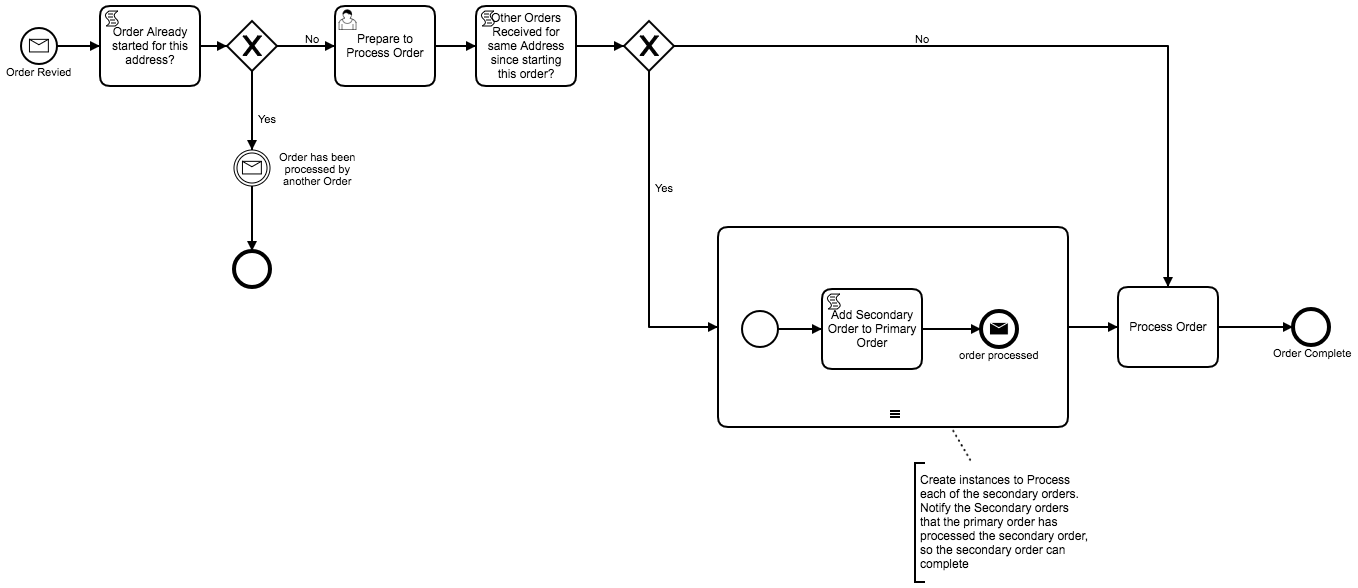
This works but my process starts like this:
- Shipping request with ID = 1 has arrived
- Retrieve shipping detail for ID = 1 and set on the process
I now need to set an async boundary after the retrieve shipping detail for the following logic to work correctly. Doing so however builds three slave processes and no master 
You get the salves because of the sub-process multi-instance, correct? Unless you are doing user tasks in the sub-process, I would probably just do the loop in the script and drop the sub-process. And in your loop in the script generate message calls to the slave orders.