Hi,
before the question itself, I would like to describe the current situation.
We are thinking about the new process application (for processing client requests), which should be used by different front-end applications (corporate web, mobile app…hosted on different infrastructure than process engine). This is the main reason, I don’t want to use forms inside the process engine for interacting with the user. Front-end applications, will be responsible for UX and calling basic process steps, and process engine will be responsible for handling the process logic and orchestration of underlying services. With this approach, also Different front-end applications (web,mobile) will use the same process.
Now, about the process…
Imagine the simple flow, where you fill-in basic info about yourself (on the front-end application screen) which triggers the start of the process.
After that, basic check is performed (by the process ,calling the backend systems) if we can find such client. If no, we will ask him to register (on the front-end application.)
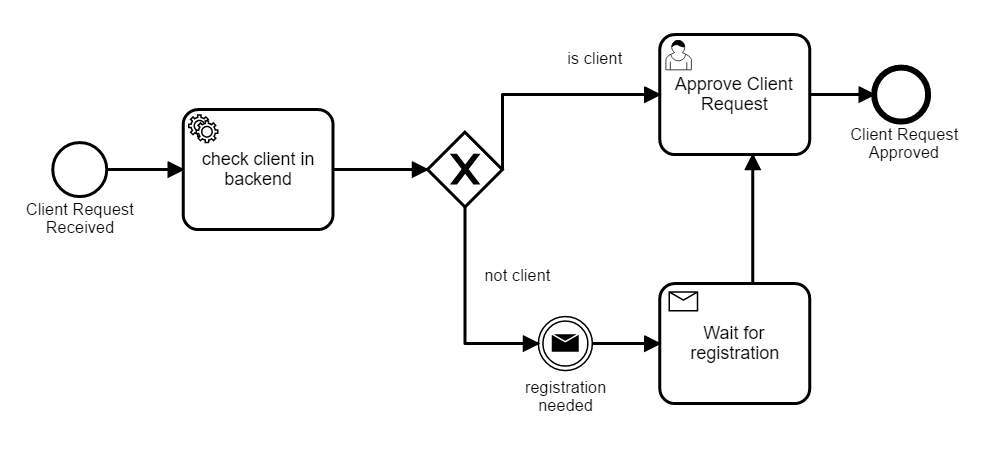
Below, you can see, how the flow looks like right now. Because I don’t have forms in my process application, I used message throwing and receiving approach, instead of User Task.
So the logic is: If no client is found in our backend systems, the process will send the message (some Rest call). The message will be identified by the front-end application (the same, where user filled-in the first set of data), and registration form will be displayed. Process will wait, for message from front-end, indicating the client was registered. After the message is received, the flow will continue to the next step.
And my question is, if you think this design of communication between process engine and front-end is a good design, or you are aware of better alternatives how to design and model this situation.
Thank you
@stanislav if you do some searching around the forum for “Page Flow” and “Multi-Step forms” you will see a bunch of different threads that talk about the pros and cons, and some of the big catch 22s.
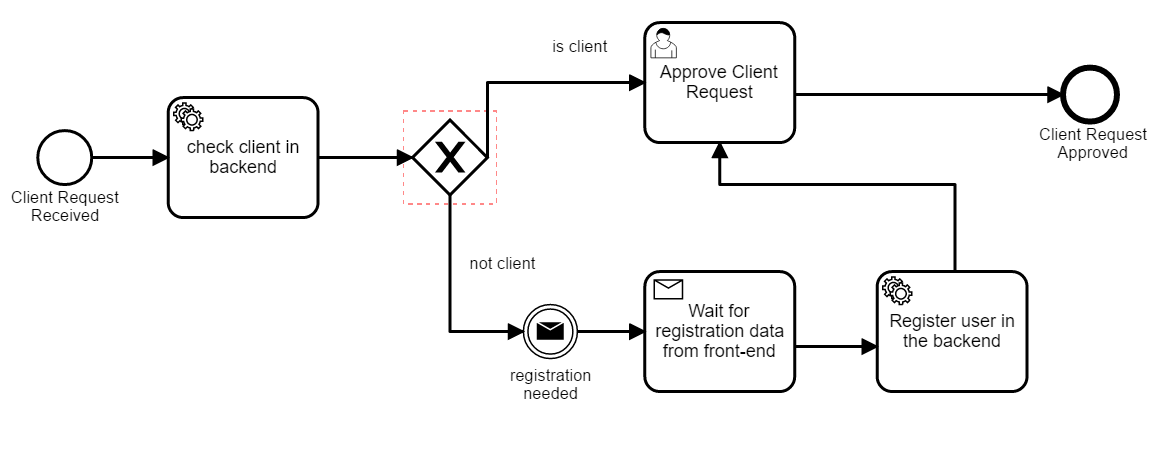
Specifically for a registration process, i am reminded of the password reset model. When you register a new user, the preferable security measure would be that a registering user cannot “Test” if another user exists. So when the user needs to register, you send them a email to them. That email has the unique link that triggers the message, and your email link would have a redirect url that takes them back to their previous page.
@stanislav also take a look at the withVariablesInReturn parameter of Start Process Instance. This can let you run a process similar to a AWS Lambda function.
You’ll need some sort of an async-capable architecture ready to handle potentially long-running process execution requests. These process models may also require async behavior (which Camunda supports).
This requirement surfaces because your Web-UI may not be able to wait for Camunda to return process results. Additionally, if Camunda spreads the work between threads, the ReST interface can’t correlate your Web-UI HTTP Requests to the Camunda BPM-engine response (v 7.6+ may address this).
In addition, a potential issue may arise if you exceed capacity of the Camunda BPM-engine host environment. The situation is where you have more HTTP-requests arriving than Camunda’s container (JBoss, etc.) can handle - basically exceeding available resources on the App-server.
So, unless you have reasonably short-running request/response type BPM models, there needs to be some sort of additional layer buffering interaction between web-UI and BPM-Engine.
My workaround generally follows features provided by Reactive (Rx) and event-driven/messaging infrastructure - both at the front and back-end services. The event-driven architecture provides additional correlation features necessary for misc. recovery scenarios.
Last note on IdM/SSO requirements, and this depends on identity pass-through requirements. OpenID related infrastructure helps solve this when following a user-centric model (or similar) whereby the user-task holds necessary credentials (in JWT if following OpenID model) for pass-through into external, integrated BPMN Task implementations.
Because the UI itself is generally disconnected or unreliably connected we’ll need some sort of async’ relationship between the front-end UI device and back-end services. This means that, as BPM/Camunda events are flowing between end-points (both front/back), there’ll be an intermediary layer negotiating the queuing and routing between system boundaries. In implementation terms this means a high-performance grid-like infrastructure. For example, Kafka is a popular choice.
With Kafka shepherding events between front and back-end components, in context we then have:
Front-end application defined by various JS libraries.
These connect into both the primary functional APIs (ReST) and system/event plumbing.
Back-end components primarily defined by BPM-models and supporting services - these also include, integration with event plumbing.
The font-end architecture requires an API-oriented design to support both the primary, user-facing features/functions (widgets, buttons, links, etc) AND an async’ capable layer either connected into or polling server-side event services.
I don’t have a current example for the front-end implementation. But, I do have a few examples of server-side integration between BPM and messaging. The code examples require a refresh… so, it’s of a rough POC quality and available on my blog and GitHub (Systems Architecture – Systems Architecture and /github.com/garysamuelson). At this point, I recommend the illustrations. The code is a bit rough.
Sorry, production examples (source code) are proprietary.
re: Lessons learned from production scaling?
Same as above. I can only reference generic, simulated scaling. Can’t provide actual production numbers.
But, on lessons learned? Yes. I’m seeing capacity plans falling short primarily due to a host/container inability to handle synchronous, blocking request/reply communication (i.e. lacking reasonable event management). The usual suspects, without fail, are HTTP clients making sync’ requests into long-running services. What happens is that an escalating number of http-sessions are left waiting on a reply from long-running business services (BPM typically but doesn’t exclude poor general resource management).
In terms of systems-thinking archetypes, it’s the classic “Tragedy of the Commons” (Senge 1990) due in no small part from poorly defined system boundaries. I see this as the anti-pattern: service-oriented functions within a process.