I have an index in MYSQL table ACT_RU_JOB by column DUEDATE_.
But today i started to see that one of our 3 pods is working so much more than the others. The cpu usage went too high, above the requested, only at that single pod:
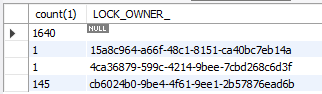
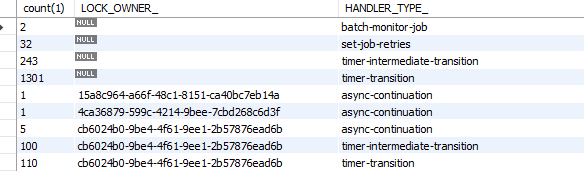
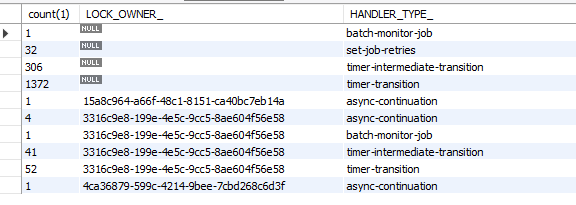
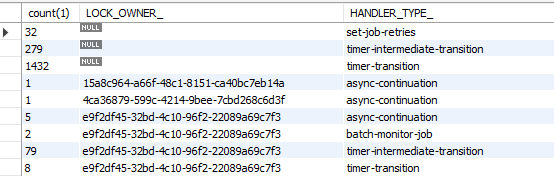
Selecting a groupby LOCK_OWNER_ at ACT_RU_JOB i could see that one single LOCK_OWNER is getting most of the jobs too, as the others are getting 1 or 2 simultaneos jobs, sometimes 10, but only one pod is getting more than 100:
As my configuration says queue-size: 10 i was expecting that one pod should never get more than 10 jobs… what am I doing wrong? there is anyway to know if camunda is reading those configurations?
The problem could be with : max-jobs-per-acquisition: 4
If you have low throughput what could be happening is that the first node grabs all the available jobs and starts working on them - when the other nodes query for jobs they don’t find any.
Because exponential back-off could be implemented, each time a node doesn’t get work it will wait longer before asking again.
This might mean that one node polls more often and keeps taking all the jobs - so maybe lowering this number will help.
Currently this project is using this versions:
org.springframework.boot:spring-boot-starter:2.0.5.RELEASE
org.camunda.bpm.springboot:camunda-bpm-spring-boot-starter:3.0.0
org.camunda.bpm:camunda-engine-plugin-spin:7.9.0
Okay, please update to 3.1.9 or higher (and Camunda along with it to stay in the compatibility matrix). The queue capacity parameter doesn’t take effect in you version as per https://jira.camunda.com/browse/CAM-11368.
we are updating our camunda from 7.9 to 7.13 starter 3.1.9, and as we expected, we got errors at deployment of our definitions, saying that the database schema is different:
Cause: org.apache.ibatis.executor.BatchExecutorException: org.camunda.bpm.engine.impl.persistence.entity.ResourceEntity.insertResource (batch index #3) failed. 2 prior sub executor(s) completed successfully, but will be rolled back. Cause: java.sql.BatchUpdateException: Unknown column ‘TYPE_’ in ‘field list’
Any guide on how to upgrade with many process instances already on production?
Im following the update guides but its safe to do it in production environment with jobs already on database?
Check the upgrade folder in the zip file for the required scripts.
Each upgrade script contains create table or alter table add column statements and it depends on the database how long a table is locked for the upgrade.
Yes, the upgrade is safe to do it in the production database. But, a backup is always good to have…